| Identification |
|---|
| HMDB Protein ID
| CDBP04712 |
| Secondary Accession Numbers
| Not Available |
| Name
| DNA topoisomerase 2-alpha |
| Description
| Not Available |
| Synonyms
|
- DNA topoisomerase II, alpha isozyme
|
| Gene Name
| TOP2A |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in sequence-specific DNA binding transcription factor activity |
| Specific Function
| Control of topological states of DNA by transient breakage and subsequent rejoining of DNA strands. Topoisomerase II makes double-strand breaks |
| GO Classification
|
| Component |
| organelle |
| membrane-bounded organelle |
| intracellular membrane-bounded organelle |
| nucleus |
| non-membrane-bounded organelle |
| intracellular non-membrane-bounded organelle |
| chromosome |
| Function |
| atp binding |
| dna topoisomerase (atp-hydrolyzing) activity |
| dna topoisomerase activity |
| nucleic acid binding |
| dna binding |
| binding |
| nucleoside binding |
| purine nucleoside binding |
| adenyl nucleotide binding |
| adenyl ribonucleotide binding |
| Process |
| metabolic process |
| macromolecule metabolic process |
| cellular macromolecule metabolic process |
| dna metabolic process |
| dna topological change |
|
| Cellular Location
|
- Nucleus
- Cytoplasm
- nucleoplasm
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Etoposide Action Pathway |   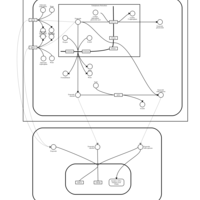 | Not Available | | Etoposide Metabolism Pathway | 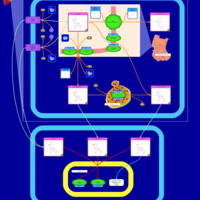  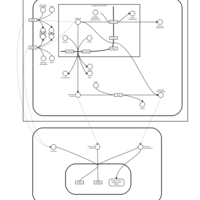 | Not Available | | Teniposide Action Pathway | 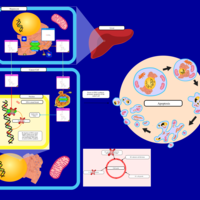 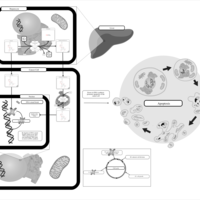 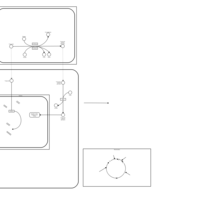 | Not Available | | Teniposide Metabolism Pathway | 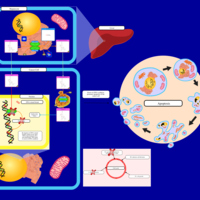 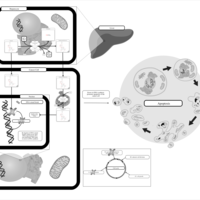  | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 17q21-q22 |
| SNPs
| TOP2A |
| Gene Sequence
|
>4596 bp
ATGGAAGTGTCACCATTGCAGCCTGTAAATGAAAATATGCAAGTCAACAAAATAAAGAAA
AATGAAGATGCTAAGAAAAGACTGTCTGTTGAAAGAATCTATCAAAAGAAAACACAATTG
GAACATATTTTGCTCCGCCCAGACACCTACATTGGTTCTGTGGAATTAGTGACCCAGCAA
ATGTGGGTTTACGATGAAGATGTTGGCATTAACTATAGGGAAGTCACTTTTGTTCCTGGT
TTGTACAAAATCTTTGATGAGATTCTAGTTAATGCTGCGGACAACAAACAAAGGGACCCA
AAAATGTCTTGTATTAGAGTCACAATTGATCCGGAAAACAATTTAATTAGTATATGGAAT
AATGGAAAAGGTATTCCTGTTGTTGAACACAAAGTTGAAAAGATGTATGTCCCAGCTCTC
ATATTTGGACAGCTCCTAACTTCTAGTAACTATGATGATGATGAAAAGAAAGTGACAGGT
GGTCGAAATGGCTATGGAGCCAAATTGTGTAACATATTCAGTACCAAATTTACTGTGGAA
ACAGCCAGTAGAGAATACAAGAAAATGTTCAAACAGACATGGATGGATAATATGGGAAGA
GCTGGTGAGATGGAACTCAAGCCCTTCAATGGAGAAGATTATACATGTATCACCTTTCAG
CCTGATTTGTCTAAGTTTAAAATGCAAAGCCTGGACAAAGATATTGTTGCACTAATGGTC
AGAAGAGCATATGATATTGCTGGATCCACCAAAGATGTCAAAGTCTTTCTTAATGGAAAT
AAACTGCCAGTAAAAGGATTTCGTAGTTATGTGGACATGTATTTGAAGGACAAGTTGGAT
GAAACTGGTAACTCCTTGAAAGTAATACATGAACAAGTAAACCACAGGTGGGAAGTGTGT
TTAACTATGAGTGAAAAAGGCTTTCAGCAAATTAGCTTTGTCAACAGCATTGCTACATCC
AAGGGTGGCAGACATGTTGATTATGTAGCTGATCAGATTGTGACTAAACTTGTTGATGTT
GTGAAGAAGAAGAACAAGGGTGGTGTTGCAGTAAAAGCACATCAGGTGAAAAATCACATG
TGGATTTTTGTAAATGCCTTAATTGAAAACCCAACCTTTGACTCTCAGACAAAAGAAAAC
ATGACTTTACAACCCAAGAGCTTTGGATCAACATGCCAATTGAGTGAAAAATTTATCAAA
GCTGCCATTGGCTGTGGTATTGTAGAAAGCATACTAAACTGGGTGAAGTTTAAGGCCCAA
GTCCAGTTAAACAAGAAGTGTTCAGCTGTAAAACATAATAGAATCAAGGGAATTCCCAAA
CTCGATGATGCCAATGATGCAGGGGGCCGAAACTCCACTGAGTGTACGCTTATCCTGACT
GAGGGAGATTCAGCCAAAACTTTGGCTGTTTCAGGCCTTGGTGTGGTTGGGAGAGACAAA
TATGGGGTTTTCCCTCTTAGAGGAAAAATACTCAATGTTCGAGAAGCTTCTCATAAGCAG
ATCATGGAAAATGCTGAGATTAACAATATCATCAAGATTGTGGGTCTTCAGTACAAGAAA
AACTATGAAGATGAAGATTCATTGAAGACGCTTCGTTATGGGAAGATAATGATTATGACA
GATCAGGACCAAGATGGTTCCCACATCAAAGGCTTGCTGATTAATTTTATCCATCACAAC
TGGCCCTCTCTTCTGCGACATCGTTTTCTGGAGGAATTTATCACTCCCATTGTAAAGGTA
TCTAAAAACAAGCAAGAAATGGCATTTTACAGCCTTCCTGAATTTGAAGAGTGGAAGAGT
TCTACTCCAAATCATAAAAAATGGAAAGTCAAATATTACAAAGGTTTGGGCACCAGCACA
TCAAAGGAAGCTAAAGAATACTTTGCAGATATGAAAAGACATCGTATCCAGTTCAAATAT
TCTGGTCCTGAAGATGATGCTGCTATCAGCCTGGCCTTTAGCAAAAAACAGATAGATGAT
CGAAAGGAATGGTTAACTAATTTCATGGAGGATAGAAGACAACGAAAGTTACTTGGGCTT
CCTGAGGATTACTTGTATGGACAAACTACCACATATCTGACATATAATGACTTCATCAAC
AAGGAACTTATCTTGTTCTCAAATTCTGATAACGAGAGATCTATCCCTTCTATGGTGGAT
GGTTTGAAACCAGGTCAGAGAAAGGTTTTGTTTACTTGCTTCAAACGGAATGACAAGCGA
GAAGTAAAGGTTGCCCAATTAGCTGGATCAGTGGCTGAAATGTCTTCTTATCATCATGGT
GAGATGTCACTAATGATGACCATTATCAATTTGGCTCAGAATTTTGTGGGTAGCAATAAT
CTAAACCTCTTGCAGCCCATTGGTCAGTTTGGTACCAGGCTACATGGTGGCAAGGATTCT
GCTAGTCCACGATACATCTTTACAATGCTCAGCTCTTTGGCTCGATTGTTATTTCCACCA
AAAGATGATCACACGTTGAAGTTTTTATATGATGACAACCAGCGTGTTGAGCCTGAATGG
TACATTCCTATTATTCCCATGGTGCTGATAAATGGTGCTGAAGGAATCGGTACTGGGTGG
TCCTGCAAAATCCCCAACTTTGATGTGCGTGAAATTGTAAATAACATCAGGCGTTTGATG
GATGGAGAAGAACCTTTGCCAATGCTTCCAAGTTACAAGAACTTCAAGGGTACTATTGAA
GAACTGGCTCCAAATCAATATGTGATTAGTGGTGAAGTAGCTATTCTTAATTCTACAACC
ATTGAAATCTCAGAGCTTCCCGTCAGAACATGGACCCAGACATACAAAGAACAAGTTCTA
GAACCCATGTTGAATGGCACCGAGAAGACACCTCCTCTCATAACAGACTATAGGGAATAC
CATACAGATACCACTGTGAAATTTGTTGTGAAGATGACTGAAGAAAAACTGGCAGAGGCA
GAGAGAGTTGGACTACACAAAGTCTTCAAACTCCAAACTAGTCTCACATGCAACTCTATG
GTGCTTTTTGACCACGTAGGCTGTTTAAAGAAATATGACACGGTGTTGGATATTCTAAGA
GACTTTTTTGAACTCAGACTTAAATATTATGGATTAAGAAAAGAATGGCTCCTAGGAATG
CTTGGTGCTGAATCTGCTAAACTGAATAATCAGGCTCGCTTTATCTTAGAGAAAATAGAT
GGCAAAATAATCATTGAAAATAAGCCTAAGAAAGAATTAATTAAAGTTCTGATTCAGAGG
GGATATGATTCGGATCCTGTGAAGGCCTGGAAAGAAGCCCAGCAAAAGGTTCCAGATGAA
GAAGAAAATGAAGAGAGTGACAACGAAAAGGAAACTGAAAAGAGTGACTCCGTAACAGAT
TCTGGACCAACCTTCAACTATCTTCTTGATATGCCCCTTTGGTATTTAACCAAGGAAAAG
AAAGATGAACTCTGCAGGCTAAGAAATGAAAAAGAACAAGAGCTGGACACATTAAAAAGA
AAGAGTCCATCAGATTTGTGGAAAGAAGACTTGGCTACATTTATTGAAGAATTGGAGGCT
GTTGAAGCCAAGGAAAAACAAGATGAACAAGTCGGACTTCCTGGGAAAGGGGGGAAGGCC
AAGGGGAAAAAAACACAAATGGCTGAAGTTTTGCCTTCTCCGCGTGGTCAAAGAGTCATT
CCACGAATAACCATAGAAATGAAAGCAGAGGCAGAAAAGAAAAATAAAAAGAAAATTAAG
AATGAAAATACTGAAGGAAGCCCTCAAGAAGATGGTGTGGAACTAGAAGGCCTAAAACAA
AGATTAGAAAAGAAACAGAAAAGAGAACCAGGTACAAAGACAAAGAAACAAACTACATTG
GCATTTAAGCCAATCAAAAAAGGAAAGAAGAGAAATCCCTGGCCTGATTCAGAATCAGAT
AGGAGCAGTGACGAAAGTAATTTTGATGTCCCTCCACGAGAAACAGAGCCACGGAGAGCA
GCAACAAAAACAAAATTCACAATGGATTTGGATTCAGATGAAGATTTCTCAGATTTTGAT
GAAAAAACTGATGATGAAGATTTTGTCCCATCAGATGCTAGTCCACCTAAGACCAAAACT
TCCCCAAAACTTAGTAACAAAGAACTGAAACCACAGAAAAGTGTCGTGTCAGACCTTGAA
GCTGATGATGTTAAGGGCAGTGTACCACTGTCTTCAAGCCCTCCTGCTACACATTTCCCA
GATGAAACTGAAATTACAAACCCAGTTCCTAAAAAGAATGTGACAGTGAAGAAGACAGCA
GCAAAAAGTCAGTCTTCCACCTCCACTACCGGTGCCAAAAAAAGGGCTGCCCCAAAAGGA
ACTAAAAGGGATCCAGCTTTGAATTCTGGTGTCTCTCAAAAGCCTGATCCTGCCAAAACC
AAGAATCGCCGCAAAAGGAAGCCATCCACTTCTGATGATTCTGACTCTAATTTTGAGAAA
ATTGTTTCGAAAGCAGTCACAAGCAAGAAATCCAAGGGGGAGAGTGATGACTTCCATATG
GACTTTGACTCAGCTGTGGCTCCTCGGGCAAAATCTGTACGGGCAAAGAAACCTATAAAG
TACCTGGAAGAGTCAGATGAAGATGATCTGTTTTAA
|
| Protein Properties |
|---|
| Number of Residues
| 1531 |
| Molecular Weight
| 174383.9 |
| Theoretical pI
| 9.17 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
|
| Protein Sequence
|
>DNA topoisomerase 2-alpha
MEVSPLQPVNENMQVNKIKKNEDAKKRLSVERIYQKKTQLEHILLRPDTYIGSVELVTQQ
MWVYDEDVGINYREVTFVPGLYKIFDEILVNAADNKQRDPKMSCIRVTIDPENNLISIWN
NGKGIPVVEHKVEKMYVPALIFGQLLTSSNYDDDEKKVTGGRNGYGAKLCNIFSTKFTVE
TASREYKKMFKQTWMDNMGRAGEMELKPFNGEDYTCITFQPDLSKFKMQSLDKDIVALMV
RRAYDIAGSTKDVKVFLNGNKLPVKGFRSYVDMYLKDKLDETGNSLKVIHEQVNHRWEVC
LTMSEKGFQQISFVNSIATSKGGRHVDYVADQIVTKLVDVVKKKNKGGVAVKAHQVKNHM
WIFVNALIENPTFDSQTKENMTLQPKSFGSTCQLSEKFIKAAIGCGIVESILNWVKFKAQ
VQLNKKCSAVKHNRIKGIPKLDDANDAGGRNSTECTLILTEGDSAKTLAVSGLGVVGRDK
YGVFPLRGKILNVREASHKQIMENAEINNIIKIVGLQYKKNYEDEDSLKTLRYGKIMIMT
DQDQDGSHIKGLLINFIHHNWPSLLRHRFLEEFITPIVKVSKNKQEMAFYSLPEFEEWKS
STPNHKKWKVKYYKGLGTSTSKEAKEYFADMKRHRIQFKYSGPEDDAAISLAFSKKQIDD
RKEWLTNFMEDRRQRKLLGLPEDYLYGQTTTYLTYNDFINKELILFSNSDNERSIPSMVD
GLKPGQRKVLFTCFKRNDKREVKVAQLAGSVAEMSSYHHGEMSLMMTIINLAQNFVGSNN
LNLLQPIGQFGTRLHGGKDSASPRYIFTMLSSLARLLFPPKDDHTLKFLYDDNQRVEPEW
YIPIIPMVLINGAEGIGTGWSCKIPNFDVREIVNNIRRLMDGEEPLPMLPSYKNFKGTIE
ELAPNQYVISGEVAILNSTTIEISELPVRTWTQTYKEQVLEPMLNGTEKTPPLITDYREY
HTDTTVKFVVKMTEEKLAEAERVGLHKVFKLQTSLTCNSMVLFDHVGCLKKYDTVLDILR
DFFELRLKYYGLRKEWLLGMLGAESAKLNNQARFILEKIDGKIIIENKPKKELIKVLIQR
GYDSDPVKAWKEAQQKVPDEEENEESDNEKETEKSDSVTDSGPTFNYLLDMPLWYLTKEK
KDELCRLRNEKEQELDTLKRKSPSDLWKEDLATFIEELEAVEAKEKQDEQVGLPGKGGKA
KGKKTQMAEVLPSPRGQRVIPRITIEMKAEAEKKNKKKIKNENTEGSPQEDGVELEGLKQ
RLEKKQKREPGTKTKKQTTLAFKPIKKGKKRNPWSDSESDRSSDESNFDVPPRETEPRRA
ATKTKFTMDLDSDEDFSDFDEKTDDEDFVPSDASPPKTKTSPKLSNKELKPQKSVVSDLE
ADDVKGSVPLSSSPPATHFPDETEITNPVPKKNVTVKKTAAKSQSSTSTTGAKKRAAPKG
TKRDPALNSGVSQKPDPAKTKNRRKRKPSTSDDSDSNFEKIVSKAVTSKKSKGESDDFHM
DFDSAVAPRAKSVRAKKPIKYLEESDEDDLF
|
| External Links |
|---|
| GenBank ID Protein
| 292830 |
| UniProtKB/Swiss-Prot ID
| P11388 |
| UniProtKB/Swiss-Prot Entry Name
| TOP2A_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| J04088 |
| GeneCard ID
| TOP2A |
| GenAtlas ID
| TOP2A |
| HGNC ID
| HGNC:11989 |
| References |
|---|
| General References
| Not Available |