| Identification |
|---|
| HMDB Protein ID
| CDBP02706 |
| Secondary Accession Numbers
| Not Available |
| Name
| Voltage-dependent P/Q-type calcium channel subunit alpha-1A |
| Description
| Not Available |
| Synonyms
|
- BI
- Brain calcium channel I
- Calcium channel, L type, alpha-1 polypeptide isoform 4
- Voltage-gated calcium channel subunit alpha Cav2.1
|
| Gene Name
| CACNA1A |
| Protein Type
| Transporter |
| Biological Properties |
|---|
| General Function
| Involved in ion channel activity |
| Specific Function
| Voltage-sensitive calcium channels (VSCC) mediate the entry of calcium ions into excitable cells and are also involved in a variety of calcium-dependent processes, including muscle contraction, hormone or neurotransmitter release, gene expression, cell motility, cell division and cell death. The isoform alpha-1A gives rise to P and/or Q-type calcium currents. P/Q-type calcium channels belong to the 'high-voltage activated' (HVA) group and are blocked by the funnel toxin (Ftx) and by the omega-agatoxin- IVA (omega-Aga-IVA). They are however insensitive to dihydropyridines (DHP), and omega-conotoxin-GVIA (omega-CTx-GVIA) |
| GO Classification
|
| Component |
| membrane |
| cell part |
| membrane part |
| ion channel complex |
| cation channel complex |
| macromolecular complex |
| intrinsic to membrane |
| protein complex |
| integral to membrane |
| calcium channel complex |
| voltage-gated calcium channel complex |
| Function |
| ion transmembrane transporter activity |
| transporter activity |
| ion channel activity |
| cation channel activity |
| calcium channel activity |
| voltage-gated calcium channel activity |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| Process |
| di-, tri-valent inorganic cation transport |
| divalent metal ion transport |
| calcium ion transport |
| establishment of localization |
| transport |
| transmembrane transport |
| ion transport |
| cation transport |
|
| Cellular Location
|
- Membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Benzocaine Action Pathway | 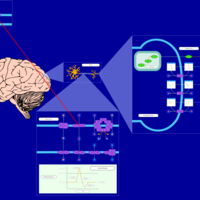   | Not Available | | Bupivacaine Action Pathway | 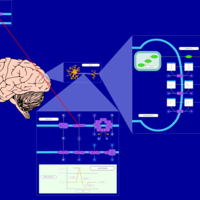   | Not Available | | Chloroprocaine Action Pathway |    | Not Available | | Cocaine Action Pathway |    | Not Available | | Dibucaine Action Pathway |    | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 19p13 |
| SNPs
| CACNA1A |
| Gene Sequence
|
>7518 bp
ATGGCCCGCTTCGGAGACGAGATGCCGGCCCGCTACGGGGGAGGAGGCTCCGGGGCAGCC
GCCGGGGTGGTCGTGGGCAGCGGAGGCGGGCGAGGAGCCGGGGGCAGCCGGCAGGGCGGG
CAGCCCGGGGCGCAAAGGATGTACAAGCAGTCAATGGCGCAGAGAGCGCGGACCATGGCA
CTCTACAACCCCATCCCCGTCCGACAGAACTGCCTCACGGTTAACCGGTCTCTCTTCCTC
TTCAGCGAAGACAACGTGGTGAGAAAATACGCCAAAAAGATCACCGAATGGCCTCCCTTT
GAATATATGATTTTAGCCACCATCATAGCGAATTGCATCGTCCTCGCACTGGAGCAGCAT
CTGCCTGATGATGACAAGACCCCGATGTCTGAACGGCTGGATGACACAGAACCATACTTC
ATTGGAATTTTTTGTTTCGAGGCTGGAATTAAAATCATTGCCCTTGGGTTTGCCTTCCAC
AAAGGCTCCTACTTGAGGAATGGCTGGAATGTCATGGACTTTGTGGTGGTGCTAACGGGC
ATCTTGGCGACAGTTGGGACGGAGTTTGACCTACGGACGCTGAGGGCAGTTCGAGTGCTG
CGGCCGCTCAAGCTGGTGTCTGGAATCCCAAGTTTACAAGTCGTCCTGAAGTCGATCATG
AAGGCGATGATCCCTTTGCTGCAGATCGGCCTCCTCCTATTTTTTGCAATCCTTATTTTT
GCAATCATAGGGTTAGAATTTTATATGGGAAAATTTCATACCACCTGCTTTGAAGAGGGG
ACAGATGACATTCAGGGTGAGTCTCCGGCTCCATGTGGGACAGAAGAGCCCGCCCGCACC
TGCCCCAATGGGACCAAATGTCAGCCCTACTGGGAAGGGCCCAACAACGGGATCACTCAG
TTCGACAACATCCTGTTTGCAGTGCTGACTGTTTTCCAGTGCATAACCATGGAAGGGTGG
ACTGATCTCCTCTACAATAGCAACGATGCCTCAGGGAACACTTGGAACTGGTTGTACTTC
ATCCCCCTCATCATCATCGGCTCCTTTTTTATGCTGAACCTTGTGCTGGGTGTGCTGTCA
GGGGAGTTTGCCAAAGAAAGGGAACGGGTGGAGAACCGGCGGGCTTTTCTGAAGCTGAGG
CGGCAACAACAGATTGAACGTGAGCTCAATGGGTACATGGAATGGATCTCAAAAGCAGAA
GAGGTGATCCTCGCCGAGGATGAAACTGACGGGGAGCAGAGGCATCCCTTTGATGGAGCT
CTGCGGAGAACCACCATAAAGAAAAGCAAGACAGATTTGCTCAACCCCGAAGAGGCTGAG
GATCAGCTGGCTGATATAGCCTCTGTGGGTTCTCCCTTCGCCCGAGCCAGCATTAAAAGT
GCCAAGCTGGAGAACTCGACCTTTTTTCACAAAAAGGAGAGGAGGATGCGTTTCTACATC
CGCCGCATGGTCAAAACTCAGGCCTTCTACTGGACTGTACTCAGTTTGGTAGCTCTCAAC
ACGCTGTGTGTTGCTATTGTTCACTACAACCAGCCCGAGTGGCTCTCCGACTTCCTTTAC
TATGCAGAATTCATTTTCTTAGGACTCTTTATGTCCGAAATGTTTATAAAAATGTACGGG
CTTGGGACGCGGCCTTACTTCCACTCTTCCTTCAACTGCTTTGACTGTGGGGTTATCATT
GGGAGCATCTTCGAGGTCATCTGGGCTGTCATAAAACCTGGCACATCCTTTGGAATCAGC
GTGTTACGAGCCCTCAGGTTATTGCGTATTTTCAAAGTCACAAAGTACTGGGCATCTCTC
AGAAACCTGGTCGTCTCTCTCCTCAACTCCATGAAGTCCATCATCAGCCTGTTGTTTCTC
CTTTTCCTGTTCATTGTCGTCTTCGCCCTTTTGGGAATGCAACTCTTCGGCGGCCAGTTT
AATTTCGATGAAGGGACTCCTCCCACCAACTTCGATACTTTTCCAGCAGCAATAATGACG
GTGTTTCAGATCCTGACGGGCGAAGACTGGAACGAGGTCATGTACGACGGGATCAAGTCT
CAGGGGGGCGTGCAGGGCGGCATGGTGTTCTCCATCTATTTCATTGTACTGACGCTCTTT
GGGAACTACACCCTCCTGAATGTGTTCTTGGCCATCGCTGTGGACAATCTGGCCAACGCC
CAGGAGCTCACCAAGGACGAGCAAGAGGAAGAAGAAGCAGCGAACCAGAAACTTGCCCTA
CAGAAAGCCAAGGAGGTGGCAGAAGTGAGTCCTCTGTCCGCGGCCAACATGTCTATAGCT
GTGAAAGAGCAACAGAAGAATCAAAAGCCAGCCAAGTCCGTGTGGGAGCAGCGGACCAGT
GAGATGCGAAAGCAGAACTTGCTGGCCAGCCGGGAGGCCCTGTATAACGAAATGGACCCG
GACGAGCGCTGGAAGGCTGCCTACACGCGGCACCTGCGGCCAGACATGAAGACGCACTTG
GACCGGCCGCTGGTGGTGGACCCGCAGGAGAACCGCAACAACAACACCAACAAGAGCCGG
GCGGCCGAGCCCACCGTGGACCAGCGCCTCGGCCAGCAGCGCGCCGAGGACTTCCTCAGG
AAACAGGCCCGCTACCACGATCGGGCCCGGGACCCCAGCGGCTCGGCGGGCCTGGACGCA
CGGAGGCCCTGGGCGGGAAGCCAGGAGGCCGAGCTGAGCCGGGAGGGACCCTACGGCCGC
GAGTCGGACCACCACGCCCGGGAGGGCAGCCTGGAGCAACCCGGGTTCTGGGAGGGCGAG
GCCGAGCGAGGCAAGGCCGGGGACCCCCACCGGAGGCACGTGCACCGGCAGGGGGGCAGC
AGGGAGAGCCGCAGCGGGTCCCCGCGCACGGGCGCGGACGGGGAGCATCGACGTCATCGC
GCGCACCGCAGGCCCGGGGAGGAGGGTCCGGAGGACAAGGCGGAGCGGAGGGCGCGGCAC
CGCGAGGGCAGCCGGCCGGCCCGGGGCGGCGAGGGCGAGGGCGAGGGCCCCGACGGGGGC
GAGCGCAGGAGAAGGCACCGGCATGGCGCTCCAGCCACGTACGAGGGGGACGCGCGGAGG
GAGGACAAGGAGCGGAGGCATCGGAGGAGGAAAGAGAACCAGGGCTCCGGGGTCCCTGTG
TCGGGCCCCAACCTGTCAACCACCCGGCCAATCCAGCAGGACCTGGGCCGCCAAGACCCA
CCCCTGGCAGAGGATATTGACAACATGAAGAACAACAAGCTGGCCACCGCGGAGTCGGCC
GCTCCCCACGGCAGCCTTGGCCACGCCGGCCTGCCCCAGAGCCCAGCCAAGATGGGAAAC
AGCACCGACCCCGGCCCCATGCTGGCCATCCCTGCCATGGCCACCAACCCCCAGAACGCC
GCCAGCCGCCGGACGCCCAACAACCCGGGGAACCCATCCAATCCCGGCCCCCCCAAGACC
CCCGAGAATAGCCTTATCGTCACCAACCCCAGCGGCACCCAGACCAATTCAGCTAAGACT
GCCAGGAAACCCGACCACACCACAGTGGACATCCCCCCAGCCTGCCCACCCCCCCTCAAC
CACACCGTCGTACAAGTGAACAAAAACGCCAACCCAGACCCACTGCCAAAAAAAGAGGAA
GAGAAGAAGGAGGAGGAGGAAGACGACCGTGGGGAAGACGGCCCTAAGCCAATGCCTCCC
TATAGCTCCATGTTCATCCTGTCCACGACCAACCCCCTTCGCCGCCTGTGCCATTACATC
CTGAACCTGCGCTACTTTGAGATGTGCATCCTCATGGTCATTGCCATGAGCAGCATCGCC
CTGGCCGCCGAGGACCCTGTGCAGCCCAACGCACCTCGGAACAACGTGCTGCGATACTTT
GACTACGTTTTTACAGGCGTCTTTACCTTTGAGATGGTGATCAAGATGATTGACCTGGGG
CTCGTCCTGCATCAGGGTGCCTACTTCCGTGACCTCTGGAATATTCTCGACTTCATAGTG
GTCAGTGGGGCCCTGGTAGCCTTTGCCTTCACTGGCAATAGCAAAGGAAAAGACATCAAC
ACGATTAAATCCCTCCGAGTCCTCCGGGTGCTACGACCTCTTAAAACCATCAAGCGGCTG
CCAAAGCTCAAGGCTGTGTTTGACTGTGTGGTGAACTCACTTAAAAACGTCTTCAACATC
CTCATCGTCTACATGCTATTCATGTTCATCTTCGCCGTGGTGGCTGTGCAGCTCTTCAAG
GGGAAATTCTTCCACTGCACTGACGAGTCCAAAGAGTTTGAGAAAGATTGTCGAGGCAAA
TACCTCCTCTACGAGAAGAATGAGGTGAAGGCGCGAGACCGGGAGTGGAAGAAGTATGAA
TTCCATTACGACAATGTGCTGTGGGCTCTGCTGACCCTCTTCACCGTGTCCACGGGAGAA
GGCTGGCCACAGGTCCTCAAGCATTCGGTGGACGCCACCTTTGAGAACCAGGGCCCCAGC
CCCGGGTACCGCATGGAGATGTCCATTTTCTACGTCGTCTACTTTGTGGTGTTCCCCTTC
TTCTTTGTCAATATCTTTGTGGCCTTGATCATCATCACCTTCCAGGAGCAAGGGGACAAG
ATGATGGAGGAATACAGCCTGGAGAAAAATGAGAGGGCCTGCATTGATTTCGCCATCAGC
GCCAAGCCGCTGACCCGACACATGCCGCAGAACAAGCAGAGCTTCCAGTACCGCATGTGG
CAGTTCGTGGTGTCTCCGCCTTTCGAGTACACGATCATGGCCATGATCGCCCTCAACACC
ATCGTGCTTATGATGAAGTTCTATGGGGCTTCTGTTGCTTATGAAAATGCCCTGCGGGTG
TTCAACATCGTCTTCACCTCCCTCTTCTCTCTGGAATGTGTGCTGAAAGTCATGGCTTTT
GGGATTCTGAATTATTTCCGCGATGCCTGGAACATCTTCGACTTTGTGACTGTTCTGGGC
AGCATCACCGATATCCTCGTGACTGAGTTTGGGAATAACTTCATCAACCTGAGCTTTCTC
CGCCTCTTCCGAGCTGCCCGGCTCATCAAACTTCTCCGTCAGGGTTACACCATCCGCATT
CTTCTCTGGACCTTTGTGCAGTCCTTCAAGGCCCTGCCTTATGTCTGTCTGCTGATCGCC
ATGCTCTTCTTCATCTATGCCATCATTGGGATGCAGGTGTTTGGTAACATTGGCATCGAC
GTGGAGGACGAGGACAGTGATGAAGATGAGTTCCAAATCACTGAGCACAATAACTTCCGG
ACCTTCTTCCAGGCCCTCATGCTTCTCTTCCGGAGTGCCACCGGGGAAGCTTGGCACAAC
ATCATGCTTTCCTGCCTCAGCGGGAAACCGTGTGATAAGAACTCTGGCATCCTGACTCGA
GAGTGTGGCAATGAATTTGCTTATTTTTACTTTGTTTCCTTCATCTTCCTCTGCTCGTTT
CTGATGCTGAATCTCTTTGTCGCCGTCATCATGGACAACTTTGAGTACCTCACCCGAGAC
TCCTCCATCCTGGGCCCCCACCACCTGGATGAGTACGTGCGTGTCTGGGCCGAGTATGAC
CCCGCAGCTTGCGGTCGGATTCATTATAAGGATATGTACAGTTTATTACGAGTAATATCT
CCCCCTCTCGGCTTAGGCAAGAAATGTCCTCATAGGGTTGCTTGCAAGCGGCTTCTGCGG
ATGGACCTGCCCGTCGCAGATGACAACACCGTCCACTTCAATTCCACCCTCATGGCTCTG
ATCCGCACAGCCCTGGACATCAAGATTGCCAAGGGAGGAGCCGACAAACAGCAGATGGAC
GCTGAGCTGCGGAAGGAGATGATGGCGATTTGGCCCAATCTGTCCCAGAAGACGCTAGAC
CTGCTGGTCACACCTCACAAGTCCACGGACCTCACCGTGGGGAAGATCTACGCAGCCATG
ATGATCATGGAGTACTACCGGCAGAGCAAGGCCAAGAAGCTGCAGGCCATGCGCGAGGAG
CAGGACCGGACACCCCTCATGTTCCAGCGCATGGAGCCCCCGTCCCCAACGCAGGAAGGG
GGACCTGGCCAGAACGCCCTCCCCTCCACCCAGCTGGACCCAGGAGGAGCCCTGATGGCT
CACGAAAGCGGCCTCAAGGAGAGCCCGTCCTGGGTGACCCAGCGTGCCCAGGAGATGTTC
CAGAAGACGGGCACATGGAGTCCGGAACAAGGCCCCCCTACCGACATGCCCAACAGCCAG
CCTAACTCTCAGTCCGTGGAGATGCGAGAGATGGGCAGAGATGGCTACTCCGACAGCGAG
CACTACCTCCCCATGGAAGGCCAGGGCCGGGCTGCCTCCATGCCCCGCCTCCCTGCAGAG
AACCAGAGGAGAAGGGGCCGGCCACGTGGGAATAACCTCAGTACCATCTCAGACACCAGC
CCCATGAAGCGTTCAGCCTCCGTGCTGGGCCCCAAGGCCCGACGCCTGGACGATTACTCG
CTGGAGCGGGTCCCGCCCGAGGAGAACCAGCGGCACCACCAGCGGCGCCGCGACCGCAGC
CACCGCGCCTCTGAGCGCTCCCTGGGCCGCTACACCGATGTGGACACAGGCTTGGGGACA
GACCTGAGCATGACCACCCAATCCGGGGACCTGCCGTCGAAGGAGCGGGACCAGGAGCGG
GGCCGGCCCAAGGATCGGAAGCATCGACAGCACCACCACCACCACCACCACCACCACCAT
CCCCCGCCCCCCGACAAGGACCGCTATGCCCAGGAACGGCCGGACCACGGCCGGGCACGG
GCTCGGGACCAGCGCTGGTCCCGCTCGCCCAGCGAGGGCCGAGAGCACATGGCGCACCGG
CAGGGCAGTAGTTCCGTAAGTGGAAGCCCAGCCCCCTCAACATCTGGTACCAGCACTCCG
CGGCGGGGCCGCCGCCAGCTCCCCCAGACCCCCTCCACCCCCCGGCCACACGTGTCCTAT
TCCCCTGTGATCCGTAAGGCCGGCGGCTCGGGGCCCCCGCAGCAGCAGCAGCAGCAGCAG
CAGCAGCAGCAGGCGGTGGCCAGGCCGGGCCGGGCGGCCACCAGCGGCCCTCGGAGGTAC
CCAGGCCCCACGGCCGAGCCTCTGGCCGGAGATCGGCCGCCCACGGGGGGCCACAGCAGC
GGCCGCTCGCCCAGGATGGAGAGGCGGGTCCCAGGCCCGGCCCGGAGCGAGTCCCCCAGG
GCCTGTCGACACGGCGGGGCCCGGTGGCCGGCATCTGGCCCGCACGTGTCCGAGGGGCCC
CCGGGTCCCCGGCACCATGGCTACTACCGGGGCTCCGACTACGACGAGGCCGATGGCCCG
GGCAGCGGGGGCGGCGAGGAGGCCATGGCCGGGGCCTACGACGCGCCACCCCCCGTACGA
CACGCGTCCTCGGGCGCCACCGGGCGCTCGCCCAGGACTCCCCGGGCCTCGGGCCCGGCC
TGCGCCTCGCCTTCTCGGCACGGCCGGCGACTCCCCAACGGCTACTACCCGGCGCACGGA
CTGGCCAGGCCCCGCGGGCCGGGCTCCAGGAAGGGCCTGCACGAACCCTACAGCGAGAGT
GACGATGATTGGTGCTAA
|
| Protein Properties |
|---|
| Number of Residues
| 2505 |
| Molecular Weight
| 282362.4 |
| Theoretical pI
| 9.1 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["99-117", "136-155", "168-185", "191-209", "229-248", "336-360", "488-506", "522-541", "550-568", "579-597", "617-636", "690-714", "1243-1261", "1278-1297", "1310-1328", "1340-1358", "1378-1397", "1485-1509", "1565-1593", "1599-1618", "1627-1645", "1653-1671", "1691-1710", "1783-1807"]
|
| Protein Sequence
|
>Voltage-dependent P/Q-type calcium channel subunit alpha-1A
MARFGDEMPARYGGGGSGAAAGVVVGSGGGRGAGGSRQGGQPGAQRMYKQSMAQRARTMA
LYNPIPVRQNCLTVNRSLFLFSEDNVVRKYAKKITEWPPFEYMILATIIANCIVLALEQH
LPDDDKTPMSERLDDTEPYFIGIFCFEAGIKIIALGFAFHKGSYLRNGWNVMDFVVVLTG
ILATVGTEFDLRTLRAVRVLRPLKLVSGIPSLQVVLKSIMKAMIPLLQIGLLLFFAILIF
AIIGLEFYMGKFHTTCFEEGTDDIQGESPAPCGTEEPARTCPNGTKCQPYWEGPNNGITQ
FDNILFAVLTVFQCITMEGWTDLLYNSNDASGNTWNWLYFIPLIIIGSFFMLNLVLGVLS
GEFAKERERVENRRAFLKLRRQQQIERELNGYMEWISKAEEVILAEDETDGEQRHPFDGA
LRRTTIKKSKTDLLNPEEAEDQLADIASVGSPFARASIKSAKLENSTFFHKKERRMRFYI
RRMVKTQAFYWTVLSLVALNTLCVAIVHYNQPEWLSDFLYYAEFIFLGLFMSEMFIKMYG
LGTRPYFHSSFNCFDCGVIIGSIFEVIWAVIKPGTSFGISVLRALRLLRIFKVTKYWASL
RNLVVSLLNSMKSIISLLFLLFLFIVVFALLGMQLFGGQFNFDEGTPPTNFDTFPAAIMT
VFQILTGEDWNEVMYDGIKSQGGVQGGMVFSIYFIVLTLFGNYTLLNVFLAIAVDNLANA
QELTKDEQEEEEAANQKLALQKAKEVAEVSPLSAANMSIAVKEQQKNQKPAKSVWEQRTS
EMRKQNLLASREALYNEMDPDERWKAAYTRHLRPDMKTHLDRPLVVDPQENRNNNTNKSR
AAEPTVDQRLGQQRAEDFLRKQARYHDRARDPSGSAGLDARRPWAGSQEAELSREGPYGR
ESDHHAREGSLEQPGFWEGEAERGKAGDPHRRHVHRQGGSRESRSGSPRTGADGEHRRHR
AHRRPGEEGPEDKAERRARHREGSRPARGGEGEGEGPDGGERRRRHRHGAPATYEGDARR
EDKERRHRRRKENQGSGVPVSGPNLSTTRPIQQDLGRQDPPLAEDIDNMKNNKLATAESA
APHGSLGHAGLPQSPAKMGNSTDPGPMLAIPAMATNPQNAASRRTPNNPGNPSNPGPPKT
PENSLIVTNPSGTQTNSAKTARKPDHTTVDIPPACPPPLNHTVVQVNKNANPDPLPKKEE
EKKEEEEDDRGEDGPKPMPPYSSMFILSTTNPLRRLCHYILNLRYFEMCILMVIAMSSIA
LAAEDPVQPNAPRNNVLRYFDYVFTGVFTFEMVIKMIDLGLVLHQGAYFRDLWNILDFIV
VSGALVAFAFTGNSKGKDINTIKSLRVLRVLRPLKTIKRLPKLKAVFDCVVNSLKNVFNI
LIVYMLFMFIFAVVAVQLFKGKFFHCTDESKEFEKDCRGKYLLYEKNEVKARDREWKKYE
FHYDNVLWALLTLFTVSTGEGWPQVLKHSVDATFENQGPSPGYRMEMSIFYVVYFVVFPF
FFVNIFVALIIITFQEQGDKMMEEYSLEKNERACIDFAISAKPLTRHMPQNKQSFQYRMW
QFVVSPPFEYTIMAMIALNTIVLMMKFYGASVAYENALRVFNIVFTSLFSLECVLKVMAF
GILNYFRDAWNIFDFVTVLGSITDILVTEFGNNFINLSFLRLFRAARLIKLLRQGYTIRI
LLWTFVQSFKALPYVCLLIAMLFFIYAIIGMQVFGNIGIDVEDEDSDEDEFQITEHNNFR
TFFQALMLLFRSATGEAWHNIMLSCLSGKPCDKNSGILTRECGNEFAYFYFVSFIFLCSF
LMLNLFVAVIMDNFEYLTRDSSILGPHHLDEYVRVWAEYDPAAWGRMPYLDMYQMLRHMS
PPLGLGKKCPARVAYKRLLRMDLPVADDNTVHFNSTLMALIRTALDIKIAKGGADKQQMD
AELRKEMMAIWPNLSQKTLDLLVTPHKSTDLTVGKIYAAMMIMEYYRQSKAKKLQAMREE
QDRTPLMFQRMEPPSPTQEGGPGQNALPSTQLDPGGALMAHESGLKESPSWVTQRAQEMF
QKTGTWSPEQGPPTDMPNSQPNSQSVEMREMGRDGYSDSEHYLPMEGQGRAASMPRLPAE
NQRRRGRPRGNNLSTISDTSPMKRSASVLGPKARRLDDYSLERVPPEENQRHHQRRRDRS
HRASERSLGRYTDVDTGLGTDLSMTTQSGDLPSKERDQERGRPKDRKHRQHHHHHHHHHH
PPPPDKDRYAQERPDHGRARARDQRWSRSPSEGREHMAHRQGSSSVSGSPAPSTSGTSTP
RRGRRQLPQTPSTPRPHVSYSPVIRKAGGSGPPQQQQQQQQQQQAVARPGRAATSGPRRY
PGPTAEPLAGDRPPTGGHSSGRSPRMERRVPGPARSESPRACRHGGARWPASGPHVSEGP
PGPRHHGYYRGSDYDEADGPGSGGGEEAMAGAYDAPPPVRHASSGATGRSPRTPRASGPA
CASPSRHGRRLPNGYYPAHGLARPRGPGSRKGLHEPYSESDDDWC
|
| External Links |
|---|
| GenBank ID Protein
| 2281752 |
| UniProtKB/Swiss-Prot ID
| O00555 |
| UniProtKB/Swiss-Prot Entry Name
| CAC1A_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| U79666 |
| GeneCard ID
| CACNA1A |
| GenAtlas ID
| CACNA1A |
| HGNC ID
| HGNC:1388 |
| References |
|---|
| General References
| Not Available |