| Identification |
|---|
| HMDB Protein ID
| CDBP02126 |
| Secondary Accession Numbers
| Not Available |
| Name
| Inositol 1,4,5-trisphosphate receptor type 1 |
| Description
| Not Available |
| Synonyms
|
- IP3 receptor isoform 1
- IP3R 1
- InsP3R1
- Type 1 InsP3 receptor
- Type 1 inositol 1,4,5-trisphosphate receptor
|
| Gene Name
| ITPR1 |
| Protein Type
| Receptor |
| Biological Properties |
|---|
| General Function
| Involved in calcium channel activity |
| Specific Function
| Intracellular channel that mediates calcium release from the endoplasmic reticulum following stimulation by inositol 1,4,5- trisphosphate |
| GO Classification
|
| Component |
| intracellular membrane-bounded organelle |
| membrane |
| cell part |
| endoplasmic reticulum |
| organelle |
| membrane-bounded organelle |
| Function |
| intracellular ligand-gated ion channel activity |
| inositol 1,4,5-trisphosphate-sensitive calcium-release channel activity |
| transmembrane transporter activity |
| substrate-specific transmembrane transporter activity |
| ion transmembrane transporter activity |
| transporter activity |
| ion channel activity |
| cation channel activity |
| calcium channel activity |
| ligand-gated ion channel activity |
| Process |
| transmembrane transport |
| ion transport |
| cation transport |
| di-, tri-valent inorganic cation transport |
| divalent metal ion transport |
| calcium ion transport |
| establishment of localization |
| transport |
|
| Cellular Location
|
- Endoplasmic reticulum membrane
- Multi-pass membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Muscle/Heart Contraction | 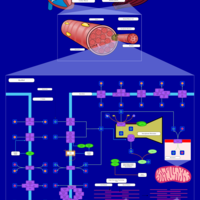 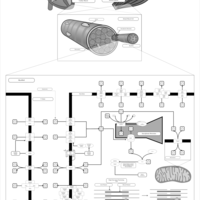  | Not Available | | Acebutolol Action Pathway | 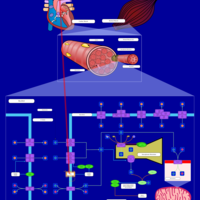 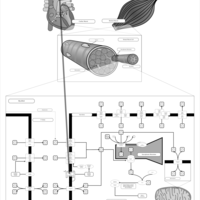  | Not Available | | Alprenolol Action Pathway | 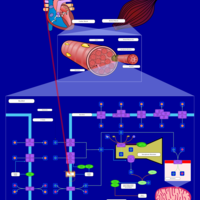 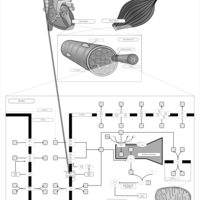  | Not Available | | Atenolol Action Pathway | 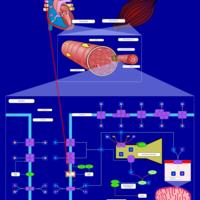 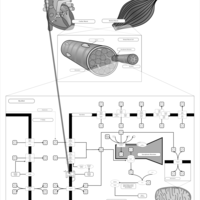  | Not Available | | Betaxolol Action Pathway | 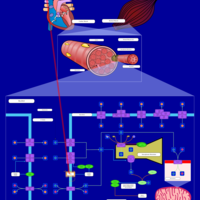   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:3 |
| Locus
| 3p26.1 |
| SNPs
| ITPR1 |
| Gene Sequence
|
>8088 bp
ATGTCTGACAAAATGTCTAGCTTCCTACATATTGGAGACATTTGTTCTCTGTACGCGGAG
GGATCGACAAATGGATTTATTAGCACCTTGGGCCTGGTTGATGATCGTTGTGTTGTACAG
CCAGAAACCGGGGACCTTAACAATCCACCTAAGAAATTCAGAGACTGCCTCTTTAAGCTA
TGTCCCATGAACCGCTACTCTGCCCAAAAGCAGTTCTGGAAAGCCGCTAAGCCTGGGGCC
AACAGCACCACAGACGCAGTGCTACTCAACAAACTGCACCACGCTGCAGACTTGGAAAAG
AAGCAGAATGAGACAGAAAACAGGAAATTGCTGGGGACCGTAATCCAGTATGGCAATGTG
ATCCAGCTCCTGCATTTGAAAAGTAATAAATACCTAACAGTGAATAAGAGGCTTCCTGCT
CTGTTGGAGAAGAATGCCATGAGAGTCACATTGGACGAGGCTGGAAATGAAGGGTCCTGG
TTTTATATTCAGCCATTCTACAAGCTGCGATCCATTGGAGACAGCGTGGTCATAGGTGAC
AAGGTGGTTCTGAACCCCGTCAATGCTGGTCAGCCCCTACATGCTAGCAGCCATCAACTG
GTAGATAACCCAGGCTGCAATGAGGTCAATTCCGTCAACTGCAATACAAGCTGGAAAATA
GTCCTTTTCATGAAATGGAGTGATAACAAAGACGACATATTAAAGGGGGGTGACGTGGTG
AGGCTGTTTCATGCTGAGCAGGAGAAGTTTCTCACCTGTGACGAACACAGGAAGAAGCAG
CACGTCTTCCTGAGAACCACGGGCCGGCAGTCGGCCACATCTGCCACCAGTTCAAAAGCC
CTGTGGGAGGTGGAGGTGGTCCAGCATGACCCATGTCGGGGCGGAGCAGGGTATTGGAAC
AGCCTTTTCCGTTTCAAGCATCTGGCCACGGGGCATTACTTGGCAGCAGAGGTGGACCCT
GATCAGGACGCCTCTCGAAGTAGGTTGCGGAATGCCCAAGAAAAGATGGTATACTCCCTG
GTCTCTGTGCCTGAAGGCAATGACATCTCCTCCATTTTCGAGCTAGATCCCACCACTCTG
CGTGGAGGTGACAGCCTTGTCCCAAGGAACTCTTATGTTCGGCTCAGACACCTATGTACT
AATACCTGGGTTCACAGCACAAATATTCCTATTGACAAGGAAGAAGAAAAGCCCGTGATG
CTGAAAATTGGCACCTCTCCTGTGAAGGAGGATAAGGAAGCATTTGCCATAGTTCCGGTT
TCTCCTGCTGAAGTTCGGGACCTGGACTTTGCCAATGATGCCAGCAAGGTGCTGGGCTCC
ATTGCTGGGAAGCTAGAGAAGGGCACCATCACCCAGAATGAAAGGAGGTCTGTAACCAAG
CTGCTAGAAGATTTGGTTTACTTCGTCACTGGTGGAACTAATTCTGGTCAAGATGTTCTC
GAAGTTGTCTTCTCCAAGCCCAACAGAGAACGGCAGAAACTGATGAGAGAACAGAATATT
CTCAAGCAGATCTTCAAGTTGTTACAAGCCCCATTCACAGACTGCGGTGATGGCCCAATG
CTTCGGCTGGAAGAGCTCGGGGACCAGCGGCACGCTCCTTTCAGACACATCTGCCGGCTC
TGCTACAGGGTGCTGAGACACTCGCAGCAAGACTACAGGAAGAACCAGGAGTATATAGCC
AAGCAGTTTGGCTTCATGCAGAAGCAGATTGGCTATGATGTGTTGGCTGAAGACACTATC
ACTGCCCTGCTCCACAATAATCGGAAACTCCTGGAAAAACACATTACCGCGGCAGAGATT
GACACATTTGTCAGCCTGGTGCGAAAGAACAGGGAGCCCAGATTCTTAGATTACCTCTCC
GACCTCTGTGTCTCCATGAACAAATCAATTCCAGTGACCCAGGAACTGATATGTAAAGCT
GTGCTGAACCCCACCAACGCTGACATCCTGATTGAGACCAAGTTGGTTCTTTCTCGTTTT
GAATTTGAAGGTGTCTCTTCCACTGGAGAGAATGCTCTGGAGGCAGGAGAAGACGAGGAA
GAGGTGTGGCTGTTTTGGAGGGACAGCAACAAAGAGATTCGCAGCAAGAGTGTGAGGGAA
TTGGCTCAGGATGCTAAAGAAGGGCAGAAGGAGGACCGAGACGTTCTCAGCTACTACAGA
TATCAGCTGAACCTCTTTGCGAGGATGTGTCTGGACCGCCAATACCTGGCCATCAACGAA
ATCTCAGGCCAGCTGGATGTCGATCTCATTCTCCGCTGCATGTCTGACGAGAACCTGCCC
TATGACCTCAGGGCGTCCTTCTGCCGCCTCATGCTTCACATGCATGTGGACCGAGATCCC
CAGGAACAAGTCACCCCCGTGAAATATGCCCGCCTCTGGTCGGAGATTCCCTCGGAGATC
GCCATTGACGACTATGATAGTAGTGGAGCTTCCAAAGATGAAATTAAGGAGAGATTTGCT
CAGACCATGGAGTTTGTGGAGGAGTATTTAAGAGATGTGGTTTGTCAGAGGTTCCCTTTC
TCTGATAAAGAGAAGAATAAGCTTACGTTTGAGGTTGTAAATTTAGCTAGGAATCTCATA
TACTTTGGTTTCTACAACTTCTCTGACCTTCTACGATTAACTAAGATCCTTCTGGCCATA
TTGGACTGTGTACATGTGACAACAATCTTCCCCATTAGCAAGATGGCGAAAGGAGAAGAG
AATAAAGGCAGTAACGTGATGAGATCTATTCATGGCGTGGGAGAGCTGATGACCCAGGTG
GTGCTCCGGGGAGGAGGCTTTTTGCCCATGACTCCCATGGCTGCTGCCCCTGAAGGCAAT
GTGAAGCAGGCAGAGCCTGAGAAGGAGGACATCATGGTCATGGACACCAAGCTGAAGATC
ATTGAGATACTCCAGTTTATTTTGAATGTGAGGTTGGATTATAGGATCTCCTGCCTCCTG
TGTATATTTAAGCGAGAGTTTGATGAAAGCAATTCCCAGACTTCAGAAACATCCTCCGGA
AACAGCAGCCAAGAAGGGCCAAGTAATGTACCAGGTGCTCTTGACTTTGAACACATTGAA
GAACAAGCAGAAGGCATCTTTGGAGGAAGTGAGGAGAACACCCCACTGGACTTGGATGAC
CACGGCGGCAGAACCTTTCTCCGTGTCCTGCTCCACTTGACGATGCATGACTACCCACCC
CTGGTGTCAGGGGCCCTGCAGCTCCTCTTCCGGCACTTCAGCCAGAGGCAGGAGGTGCTC
CAGGCCTTCAAACAGGTTCAACTGCTGGTTACCAGCCAAGATGTGGACAACTACAAACAG
ATCAAACAAGACTTGGATCAACTGAGGTCCATCGTGGAAAAGTCAGAGCTTTGGGTGTAC
AAAGGGCAGGGCCCCGATGAGACTATGGATGGTGCATCTGGAGAAAATGAACATAAGAAA
ACGGAGGAGGGAAATAACAAGCCACAAAAGCATGAAAGCACCAGCAGCTACAACTACAGA
GTGGTCAAAGAGATTTTGATTCGGCTTAGCAAACTCTGTGTTCAAGAGAGTGCCTCAGTG
AGAAAGAGCAGGAAGCAGCAACAGCGTCTGCTCCGGAACATGGGCGCGCACGCCGTGGTG
CTGGAGCTGCTGCAGATTCCCTATGAGAAGGCCGAAGATACCAAGATGCAAGAGATAATG
AGGTTGGCTCATGAATTTTTGCAGAATTTCTGCGCAGGCAACCAGCAGAATCAAGCTTTG
CTACATAAACACATAAACCTGTTTCTCAACCCAGGGATCCTGGAGGCAGTAACCATGCAG
CACATCTTCATGAACAATTTCCAGCTTTGCAGTGAGATCAACGAGAGAGTTGTTCAGCAC
TTCGTTCACTGCATAGAGACTCACGGTCGGAATGTCCAGTATATAAAGTTCTTACAGACA
ATTGTCAAGGCAGAAGGGAAATTTATTAAAAAATGCCAAGACATGGTTATGGCCGAGCTG
GTCAATTCGGGAGAGGATGTCCTCGTGTTCTACAACGACAGAGCCTCTTTCCAGACTCTG
ATCCAGATGATGCGGTCAGAACGGGATCGGATGGATGAGAACAGCCCTCTCATGTACCAC
ATCCACTTGGTCGAGCTCCTGGCTGTGTGCACGGAGGGTAAGAATGTCTACACAGAGATC
AAGTGCAACTCCCTGCTCCCGCTGGATGACATCGTTCGCGTGGTGACCCACGAGGACTGC
ATCCCTGAGGTTAAAATTGCATACATTAACTTCCTGAATCACTGCTATGTGGATACAGAG
GTGGAAATGAAGGAGATTTATACCAGCAATCACATGTGGAAATTGTTTGAGAATTTCCTT
GTAGACATCTGCAGGGCCTGTAACAACACTAGTGACAGGAAACATGCAGACTCGATTTTG
GAGAAGTATGTCACCGAAATCGTCATGAGTATTGTTACTACTTTCTTCAGCTCTCCCTTC
TCAGACCAGAGTACGACTTTGCAGACTCGCCAGCCTGTCTTTGTGCAACTGCTGCAAGGC
GTGTTCAGGGTTTACCACTGCAACTGGTTAATGCCAAGCCAAAAAGCCTCCGTGGAGAGC
TGTATTCGGGTGCTGTCTGATGTAGCCAAGAGCCGGGCCATTGCCATTCCCGTGGACCTG
GACAGCCAAGTCAACAACCTCTTTCTCAAGTCCCACAGCATTGTGCAGAAAACAGCCATG
AACTGGCGGCTCTCAGCCCGCAATGCCGCACGCAGGGACTCTGTTCTGGCAGCTTCCAGA
GACTACCGGAATATCATTGAGAGATTGCAGGACATCGTCTCCGCGCTGGAGGACCGTCTC
AGGCCCCTGGTGCAGGCAGAGTTATCTGTGCTCGTGGATGTTCTCCACAGACCCGAGCTG
CTTTTCCCAGAGAACACAGACGCCAGAAGGAAATGTGAAAGTGGCGGTTTCATTTGCAAG
TTAATAAAGCATACAAAACAGCTGCTAGAAGAAAATGAAGAGAAGCTCTGCATTAAGGTC
CTACAGACCCTGAGGGAAATGATGACCAAAGATAGAGGCTATGGAGAAAAGGGTGAGGCG
CTCAGGCAAGTTCTGGTCAACCGTTACTATGGAAACGTCAGACCTTCGGGACGAAGAGAG
AGCCTTACCAGCTTTGGCAATGGCCCACTGTCAGCAGGAGGACCCGGCAAGCCCGGGGGA
GGAGGGGGAGGTTCCGGATCCAGCTCTATGAGCAGGGGTGAGATGAGTCTGGCCGAGGTT
CAGTGTCACCTTGACAAGGAGGGGGCTTCCAATCTAGTTATCGACCTCATCATGAACGCA
TCCAGTGACCGAGTGTTCCATGAAAGCATTCTCCTGGCCATTGCCCTTCTGGAAGGAGGC
AACACCACCATCCAGCACTCCTTTTTCTGTCGCTTGACAGAAGATAAGAAGTCAGAGAAA
TTCTTTAAGGTGTTTTATGACCGGATGAAGGTGGCCCAGCAAGAAATCAAAGCAACAGTG
ACAGTGAACACCAGTGACTTGGGAAATAAAAAGAAAGACGATGAGGTAGACAGGGATGCC
CCATCACGGAAAAAAGCTAAAGAGCCCACAACACAGATAACAGAAGAGGTCCGGGATCAG
CTCCTGGAGGCCTCCGCTGCCACCAGGAAAGCCTTCACCACTTTCAGGAGGGAGGCTGAT
CCCGACGACCACTACCAGCCTGGAGAGGGCACCCAGGCCACTGCCGACAAGGCCAAGGAC
GACCTGGAGATGAGCGCGGTCATCACCATCATGCAGCCCATCCTCCGCTTCCTTCAGCTC
CTGTGTGAAAACCACAACCGAGACCTGCAGAACTTCCTCCGTTGCCAAAATAACAAGACC
AACTACAATTTGGTATGTGAGACCCTGCAGTTTCTGGACTGTATTTGTGGAAGCACAACT
GGAGGCCTTGGTCTTCTGGGCTTGTATATAAATGAAAAGAACGTAGCGCTTATCAACCAA
ACCCTGGAAAGTCTGACCGAATACTGTCAAGGACCTTGCCATGAGAACCAGAACTGCATA
GCCACCCATGAATCCAATGGCATTGACATCATCACAGCCCTGATCCTCAATGATATCAAT
CCTTTGGGAAAGAAGAGGATGGACCTTGTGTTAGAACTGAAGAACAATGCCTCGAAGTTG
CTCCTGGCCATCATGGAAAGCAGGCACGACAGTGAAAACGCAGAGAGGATACTTTATAAC
ATGAGGCCCAAGGAACTGGTGGAAGTGATCAAGAAAGCCTACATGCAAGGTGAAGTGGAA
TTTGAGGATGGAGAAAACGGTGAGGATGGGGCGGCGTCCCCCAGGAACGTGGGGCACAAC
ATCTACATATTAGCCCATCAGTTGGCTCGGCATAACAAAGAACTTCAGAGCATGCTGAAA
CCTGGTGGCCAAGTGGACGGAGATGAAGCCCTGGAGTTTTATGCCAAGCACACGGCGCAG
ATAGAGATTGTCAGATTAGACCGAACAATGGAACAGATAGTCTTTCCCGTGCCCAGCATA
TGTGAATTCCTAACCAAGGAGTCAAAACTACGAATTTACTATACTACAGAGAGAGACGAA
CAAGGCAGCAAAATCAATGATTTCTTTCTGCGGTCTGAAGACCTCTTCAATGAAATGAAT
TGGCAGAAGAAACTGAGAGCCCAGCCCGTGTTGTACTGGTGTGCCCGCAACATGTCTTTC
TGGAGCAGCATTTCGTTTAACCTGGCCGTCCTGATGAACCTGCTGGTGGCGTTTTTCTAC
CCGTTTAAGGGAGTCCGAGGAGGAACCCTGGAGCCCCACTGGTCGGGACTCCTGTGGACA
GCCATGCTCATCTCTCTGGCCATCGTCATTGCCCTCCCCAAGCCCCATGGCATCCGGGCC
TTAATTGCCTCCACAATTCTACGACTGATATTTTCAGTCGGGTTACAACCCACGTTGTTT
CTTCTGGGCGCTTTCAATGTATGCAATAAAATCATCTTTCTAATGAGCTTTGTGGGCAAC
TGTGGGACATTCACAAGAGGCTACCGAGCCATGGTTCTGGATGTTGAGTTCCTCTATCAT
TTGTTGTATCTGGTGATCTGTGCCATGGGGCTCTTTGTCCATGAATTCTTCTACAGTCTG
CTGCTTTTTGATTTAGTGTACAGAGAAGAGACTTTGCTTAATGTCATTAAAAGTGTCACT
CGCAATGGACGGTCCATCATCCTGACAGCAGTTCTGGCTCTGATCCTCGTTTACCTGTTC
TCAATAGTGGGCTATCTTTTCTTCAAGGATGACTTTATCTTGGAAGTAGATAGGCTGCCC
AATGAAACAGCTGTTCCAGAAACCGGCGAGAGTTTGGCAAGCGAGTTCCTGTTCTCCGAT
GTGTGTAGGGTGGAGAGTGGGGAGAACTGCTCCTCTCCTGCACCCAGAGAAGAGCTGGTC
CCTGCAGAAGAGACGGAACAGGATAAAGAGCACACATGTGAGACGCTGCTGATGTGCATT
GTCACTGTGCTGAGTCACGGGCTGCGGAGCGGGGGTGGAGTAGGAGATGTACTCAGGAAG
CCGTCCAAAGAGGAACCCCTGTTTGCTGCTAGAGTTATTTATGACCTCTTGTTCTTCTTC
ATGGTCATCATCATTGTTCTTAACCTGATTTTTGGGGTTATCATTGACACTTTTGCTGAC
CTGAGGAGTGAGAAGCAGAAGAAGGAAGAGATCTTGAAGACCACGTGCTTTATCTGTGGC
TTGGAAAGAGACAAGTTTGACAACAAGACTGTCACCTTTGAAGAGCACATCAAGGAAGAA
CACAACATGTGGCACTATCTGTGCTTCATCGTCCTGGTGAAAGTAAAGGACTCCACCGAA
TATACTGGGCCTGAGAGTTACGTGGCAGAAATGATCAAGGAAAGAAACCTTGACTGGTTC
CCCAGGATGAGAGCCATGTCATTGGTCAGCAGTGATTCTGAAGGAGAACAGAATGAGCTG
AGAAACCTGCAGGAGAAGCTGGAGTCCACCATGAAACTTGTCACGAACCTTTCTGGCCAG
CTGTCGGAATTAAAGGATCAGATGACAGAACAAAGGAAGCAGAAACAAAGAATTGGTCTT
CTAGGACATCCTCCTCACATGAATGTCAACCCACAACAACCAGCATAA
|
| Protein Properties |
|---|
| Number of Residues
| 2758 |
| Molecular Weight
| 313942.4 |
| Theoretical pI
| 5.91 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
- ["2283-2303", "2315-2335", "2362-2382", "2406-2426", "2449-2469", "2578-2598"]
|
| Protein Sequence
|
>Inositol 1,4,5-trisphosphate receptor type 1
MSDKMSSFLHIGDICSLYAEGSTNGFISTLGLVDDRCVVQPETGDLNNPPKKFRDCLFKL
CPMNRYSAQKQFWKAAKPGANSTTDAVLLNKLHHAADLEKKQNETENRKLLGTVIQYGNV
IQLLHLKSNKYLTVNKRLPALLEKNAMRVTLDEAGNEGSWFYIQPFYKLRSIGDSVVIGD
KVVLNPVNAGQPLHASSHQLVDNPGCNEVNSVNCNTSWKIVLFMKWSDNKDDILKGGDVV
RLFHAEQEKFLTCDEHRKKQHVFLRTTGRQSATSATSSKALWEVEVVQHDPCRGGAGYWN
SLFRFKHLATGHYLAAEVDPDFEEECLEFQPSVDPDQDASRSRLRNAQEKMVYSLVSVPE
GNDISSIFELDPTTLRGGDSLVPRNSYVRLRHLCTNTWVHSTNIPIDKEEEKPVMLKIGT
SPVKEDKEAFAIVPVSPAEVRDLDFANDASKVLGSIAGKLEKGTITQNERRSVTKLLEDL
VYFVTGGTNSGQDVLEVVFSKPNRERQKLMREQNILKQIFKLLQAPFTDCGDGPMLRLEE
LGDQRHAPFRHICRLCYRVLRHSQQDYRKNQEYIAKQFGFMQKQIGYDVLAEDTITALLH
NNRKLLEKHITAAEIDTFVSLVRKNREPRFLDYLSDLCVSMNKSIPVTQELICKAVLNPT
NADILIETKLVLSRFEFEGVSSTGENALEAGEDEEEVWLFWRDSNKEIRSKSVRELAQDA
KEGQKEDRDVLSYYRYQLNLFARMCLDRQYLAINEISGQLDVDLILRCMSDENLPYDLRA
SFCRLMLHMHVDRDPQEQVTPVKYARLWSEIPSEIAIDDYDSSGASKDEIKERFAQTMEF
VEEYLRDVVCQRFPFSDKEKNKLTFEVVNLARNLIYFGFYNFSDLLRLTKILLAILDCVH
VTTIFPISKMAKGEENKGNNDVEKLKSSNVMRSIHGVGELMTQVVLRGGGFLPMTPMAAA
PEGNVKQAEPEKEDIMVMDTKLKIIEILQFILNVRLDYRISCLLCIFKREFDESNSQTSE
TSSGNSSQEGPSNVPGALDFEHIEEQAEGIFGGSEENTPLDLDDHGGRTFLRVLLHLTMH
DYPPLVSGALQLLFRHFSQRQEVLQAFKQVQLLVTSQDVDNYKQIKQDLDQLRSIVEKSE
LWVYKGQGPDETMDGASGENEHKKTEEGNNKPQKHESTSSYNYRVVKEILIRLSKLCVQE
SASVRKSRKQQQRLLRNMGAHAVVLELLQIPYEKAEDTKMQEIMRLAHEFLQNFCAGNQQ
NQALLHKHINLFLNPGILEAVTMQHIFMNNFQLCSEINERVVQHFVHCIETHGRNVQYIK
FLQTIVKAEGKFIKKCQDMVMAELVNSGEDVLVFYNDRASFQTLIQMMRSERDRMDENSP
LMYHIHLVELLAVCTEGKNVYTEIKCNSLLPLDDIVRVVTHEDCIPEVKIAYINFLNHCY
VDTEVEMKEIYTSNHMWKLFENFLVDICRACNNTSDRKHADSILEKYVTEIVMSIVTTFF
SSPFSDQSTTLQTRQPVFVQLLQGVFRVYHCNWLMPSQKASVESCIRVLSDVAKSRAIAI
PVDLDSQVNNLFLKSHSIVQKTAMNWRLSARNAARRDSVLAASRDYRNIIERLQDIVSAL
EDRLRPLVQAELSVLVDVLHRPELLFPENTDARRKCESGGFICKLIKHTKQLLEENEEKL
CIKVLQTLREMMTKDRGYGEKLISIDELDNAELPPAPDSENSTEELEPSPPLRQLEDHKR
GEALRQVLVNRYYGNVRPSGRRESLTSFGNGPLSAGGPGKPGGGGGGSGSSSMSRGEMSL
AEVQCHLDKEGASNLVIDLIMNASSDRVFHESILLAIALLEGGNTTIQHSFFCRLTEDKK
SEKFFKVFYDRMKVAQQEIKATVTVNTSDLGNKKKDDEVDRDAPSRKKAKEPTTQITEEV
RDQLLEASAATRKAFTTFRREADPDDHYQPGEGTQATADKAKDDLEMSAVITIMQPILRF
LQLLCENHNRDLQNFLRCQNNKTNYNLVCETLQFLDCICGSTTGGLGLLGLYINEKNVAL
INQTLESLTEYCQGPCHENQNCIATHESNGIDIITALILNDINPLGKKRMDLVLELKNNA
SKLLLAIMESRHDSENAERILYNMRPKELVEVIKKAYMQGEVEFEDGENGEDGAASPRNV
GHNIYILAHQLARHNKELQSMLKPGGQVDGDEALEFYAKHTAQIEIVRLDRTMEQIVFPV
PSICEFLTKESKLRIYYTTERDEQGSKINDFFLRSEDLFNEMNWQKKLRAQPVLYWCARN
MSFWSSISFNLAVLMNLLVAFFYPFKGVRGGTLEPHWSGLLWTAMLISLAIVIALPKPHG
IRALIASTILRLIFSVGLQPTLFLLGAFNVCNKIIFLMSFVGNCGTFTRGYRAMVLDVEF
LYHLLYLVICAMGLFVHEFFYSLLLFDLVYREETLLNVIKSVTRNGRSIILTAVLALILV
YLFSIVGYLFFKDDFILEVDRLPNETAVPETGESLASEFLFSDVCRVESGENCSSPAPRE
ELVPAEETEQDKEHTCETLLMCIVTVLSHGLRSGGGVGDVLRKPSKEEPLFAARVIYDLL
FFFMVIIIVLNLIFGVIIDTFADLRSEKQKKEEILKTTCFICGLERDKFDNKTVTFEEHI
KEEHNMWHYLCFIVLVKVKDSTEYTGPESYVAEMIKERNLDWFPRMRAMSLVSSDSEGEQ
NELRNLQEKLESTMKLVTNLSGQLSELKDQMTEQRKQKQRIGLLGHPPHMNVNPQQPA
|
| External Links |
|---|
| GenBank ID Protein
| 269954692 |
| UniProtKB/Swiss-Prot ID
| Q14643 |
| UniProtKB/Swiss-Prot Entry Name
| ITPR1_HUMAN |
| PDB IDs
|
|
| GenBank Gene ID
| Not Available |
| GeneCard ID
| ITPR1 |
| GenAtlas ID
| ITPR1 |
| HGNC ID
| HGNC:6180 |
| References |
|---|
| General References
| Not Available |