| Identification |
|---|
| HMDB Protein ID
| CDBP01583 |
| Secondary Accession Numbers
| Not Available |
| Name
| Collagen alpha-1(I) chain |
| Description
| Not Available |
| Synonyms
|
- Alpha-1 type I collagen
|
| Gene Name
| COL1A1 |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in extracellular matrix structural constituent |
| Specific Function
| Type I collagen is a member of group I collagen (fibrillar forming collagen) |
| GO Classification
|
| Component |
| extracellular region part |
| collagen |
| extracellular matrix part |
| Function |
| structural molecule activity |
| extracellular matrix structural constituent |
|
| Cellular Location
|
- Secreted
- extracellular space
- extracellular matrix
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Acenocoumarol Action Pathway |    | Not Available | | Coagulation |    | Not Available | | Enoxaparin Action Pathway | 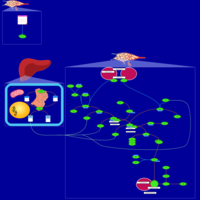   | Not Available | | Fondaparinux Action Pathway | 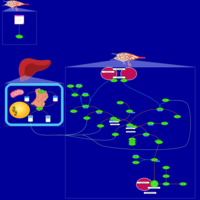   | Not Available | | Heparin Action Pathway |    | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 17q21.33 |
| SNPs
| COL1A1 |
| Gene Sequence
|
>4395 bp
ATGTTCAGCTTTGTGGACCTCCGGCTCCTGCTCCTCTTAGCGGCCACCGCCCTCCTGACG
CACGGCCAAGAGGAAGGCCAAGTCGAGGGCCAAGACGAAGACATCCCACCAATCACCTGC
GTACAGAACGGCCTCAGGTACCATGACCGAGACGTGTGGAAACCCGAGCCCTGCCGGATC
TGCGTCTGCGACAACGGCAAGGTGTTGTGCGATGACGTGATCTGTGACGAGACCAAGAAC
TGCCCCGGCGCCGAAGTCCCCGAGGGCGAGTGCTGTCCCGTCTGCCCCGACGGCTCAGAG
TCACCCACCGACCAAGAAACCACCGGCGTCGAGGGACCCAAGGGAGACACTGGCCCCCGA
GGCCCAAGGGGACCCGCAGGCCCCCCTGGCCGAGATGGCATCCCTGGACAGCCTGGACTT
CCCGGACCCCCCGGACCCCCCGGACCTCCCGGACCCCCTGGCCTCGGAGGAAACTTTGCT
CCCCAGCTGTCTTATGGCTATGATGAGAAATCAACCGGAGGAATTTCCGTGCCTGGCCCC
ATGGGTCCCTCTGGTCCTCGTGGTCTCCCTGGCCCCCCTGGTGCACCTGGTCCCCAAGGC
TTCCAAGGTCCCCCTGGTGAGCCTGGCGAGCCTGGAGCTTCAGGTCCCATGGGTCCCCGA
GGTCCCCCAGGTCCCCCTGGAAAGAATGGAGATGATGGGGAAGCTGGAAAACCTGGTCGT
CCTGGTGAGCGTGGGCCTCCTGGGCCTCAGGGTGCTCGAGGATTGCCCGGAACAGCTGGC
CTCCCTGGAATGAAGGGACACAGAGGTTTCAGTGGTTTGGATGGTGCCAAGGGAGATGCT
GGTCCTGCTGGTCCTAAGGGTGAGCCTGGCAGCCCTGGTGAAAATGGAGCTCCTGGTCAG
ATGGGCCCCCGTGGCCTGCCTGGTGAGAGAGGTCGCCCTGGAGCCCCTGGCCCTGCTGGT
GCTCGTGGAAATGATGGTGCTACTGGTGCTGCCGGGCCCCCTGGTCCCACCGGCCCCGCT
GGTCCTCCTGGCTTCCCTGGTGCTGTTGGTGCTAAGGGTGAAGCTGGTCCCCAAGGGCCC
CGAGGCTCTGAAGGTCCCCAGGGTGTGCGTGGTGAGCCTGGCCCCCCTGGCCCTGCTGGT
GCTGCTGGCCCTGCTGGAAACCCTGGTGCTGATGGACAGCCTGGTGCTAAAGGTGCCAAT
GGTGCTCCTGGTATTGCTGGTGCTCCTGGCTTCCCTGGTGCCCGAGGCCCCTCTGGACCC
CAGGGCCCCGGCGGCCCTCCTGGTCCCAAGGGTAACAGCGGTGAACCTGGTGCTCCTGGC
AGCAAAGGAGACACTGGTGCTAAGGGAGAGCCTGGCCCTGTTGGTGTTCAAGGACCCCCT
GGCCCTGCTGGAGAGGAAGGAAAGCGAGGAGCTCGAGGTGAACCCGGACCCACTGGCCTG
CCCGGACCCCCTGGCGAGCGTGGTGGACCTGGTAGCCGTGGTTTCCCTGGCGCAGATGGT
GTTGCTGGTCCCAAGGGTCCCGCTGGTGAACGTGGTTCTCCTGGCCCCGCTGGCCCCAAA
GGATCTCCTGGTGAAGCTGGTCGTCCCGGTGAAGCTGGTCTGCCTGGTGCCAAGGGTCTG
ACTGGAAGCCCTGGCAGCCCTGGTCCTGATGGCAAAACTGGCCCCCCTGGTCCCGCCGGT
CAAGATGGTCGCCCCGGACCCCCAGGCCCACCTGGTGCCCGTGGTCAGGCTGGTGTGATG
GGATTCCCTGGACCTAAAGGTGCTGCTGGAGAGCCCGGCAAGGCTGGAGAGCGAGGTGTT
CCCGGACCCCCTGGCGCTGTCGGTCCTGCTGGCAAAGATGGAGAGGCTGGAGCTCAGGGA
CCCCCTGGCCCTGCTGGTCCCGCTGGCGAGAGAGGTGAACAAGGCCCTGCTGGCTCCCCC
GGATTCCAGGGTCTCCCTGGTCCTGCTGGTCCTCCAGGTGAAGCAGGCAAACCTGGTGAA
CAGGGTGTTCCTGGAGACCTTGGCGCCCCTGGCCCCTCTGGAGCAAGAGGCGAGAGAGGT
TTCCCTGGCGAGCGTGGTGTGCAAGGTCCCCCTGGTCCTGCTGGACCCCGAGGGGCCAAC
GGTGCTCCCGGCAACGATGGTGCTAAGGGTGATGCTGGTGCCCCTGGAGCTCCCGGTAGC
CAGGGCGCCCCTGGCCTTCAGGGAATGCCTGGTGAACGTGGTGCAGCTGGTCTTCCAGGG
CCTAAGGGTGACAGAGGTGATGCTGGTCCCAAAGGTGCTGATGGCTCTCCTGGCAAAGAT
GGCGTCCGTGGTCTGACCGGCCCCATTGGTCCTCCTGGCCCTGCTGGTGCCCCTGGTGAC
AAGGGTGAAAGTGGTCCCAGCGGCCCTGCTGGTCCCACTGGAGCTCGTGGTGCCCCCGGA
GACCGTGGTGAGCCTGGTCCCCCCGGCCCTGCTGGCTTTGCTGGCCCCCCTGGTGCTGAC
GGCCAACCTGGTGCTAAAGGCGAACCTGGTGATGCTGGTGCCAAAGGCGATGCTGGTCCC
CCTGGGCCTGCCGGACCCGCTGGACCCCCTGGCCCCATTGGTAATGTTGGTGCTCCTGGA
GCCAAAGGTGCTCGCGGCAGCGCTGGTCCCCCTGGTGCTACTGGTTTCCCTGGTGCTGCT
GGCCGAGTCGGTCCTCCTGGCCCCTCTGGAAATGCTGGACCCCCTGGCCCTCCTGGTCCT
GCTGGCAAAGAAGGCGGCAAAGGTCCCCGTGGTGAGACTGGCCCTGCTGGACGTCCTGGT
GAAGTTGGTCCCCCTGGTCCCCCTGGCCCTGCTGGCGAGAAAGGATCCCCTGGTGCTGAT
GGTCCTGCTGGTGCTCCTGGTACTCCCGGGCCTCAAGGTATTGCTGGACAGCGTGGTGTG
GTCGGCCTGCCTGGTCAGAGAGGAGAGAGAGGCTTCCCTGGTCTTCCTGGCCCCTCTGGT
GAACCTGGCAAACAAGGTCCCTCTGGAGCAAGTGGTGAACGTGGTCCCCCCGGTCCCATG
GGCCCCCCTGGATTGGCTGGACCCCCTGGTGAATCTGGACGTGAGGGGGCTCCTGCTGCC
GAAGGTTCCCCTGGACGAGACGGTTCTCCTGGCGCCAAGGGTGACCGTGGTGAGACCGGC
CCCGCTGGACCCCCTGGTGCTCCTGGTGCTCCTGGTGCCCCTGGCCCCGTTGGCCCTGCT
GGCAAGAGTGGTGATCGTGGTGAGACTGGTCCTGCTGGTCCCGCCGGTCCCGTCGGCCCC
GTCGGCGCCCGTGGCCCCGCCGGACCCCAAGGCCCCCGTGGTGACAAGGGTGAGACAGGC
GAACAGGGCGACAGAGGCATAAAGGGTCACCGTGGCTTCTCTGGCCTCCAGGGTCCCCCT
GGCCCTCCTGGCTCTCCTGGTGAACAAGGTCCCTCTGGAGCCTCTGGTCCTGCTGGTCCC
CGAGGTCCCCCTGGCTCTGCTGGTGCTCCTGGCAAAGATGGACTCAACGGTCTCCCTGGC
CCCATTGGGCCCCCTGGTCCTCGCGGTCGCACTGGTGATGCTGGTCCTGTTGGTCCCCCC
GGCCCTCCTGGACCTCCTGGTCCCCCTGGTCCTCCCAGCGCTGGTTTCGACTTCAGCTTC
CTGCCCCAGCCACCTCAAGAGAAGGCTCACGATGGTGGCCGCTACTACCGGGCTGATGAT
GCCAATGTGGTTCGTGACCGTGACCTCGAGGTGGACACCACCCTCAAGAGCCTGAGCCAG
CAGATCGAGAACATCCGGAGCCCAGAGGGAAGCCGCAAGAACCCCGCCCGCACCTGCCGT
GACCTCAAGATGTGCCACTCTGACTGGAAGAGTGGAGAGTACTGGATTGACCCCAACCAA
GGCTGCAACCTGGATGCCATCAAAGTCTTCTGCAACATGGAGACTGGTGAGACCTGCGTG
TACCCCACTCAGCCCAGTGTGGCCCAGAAGAACTGGTACATCAGCAAGAACCCCAAGGAC
AAGAGGCATGTCTGGTTCGGCGAGAGCATGACCGATGGATTCCAGTTCGAGTATGGCGGC
CAGGGCTCCGACCCTGCCGATGTGGCCATCCAGCTGACCTTCCTGCGCCTGATGTCCACC
GAGGCCTCCCAGAACATCACCTACCACTGCAAGAACAGCGTGGCCTACATGGACCAGCAG
ACTGGCAACCTCAAGAAGGCCCTGCTCCTCAAGGGCTCCAACGAGATCGAGATCCGCGCC
GAGGGCAACAGCCGCTTCACCTACAGCGTCACTGTCGATGGCTGCACGAGTCACACCGGA
GCCTGGGGCAAGACAGTGATTGAATACAAAACCACCAAGTCCTCCCGCCTGCCCATCATC
GATGTGGCCCCCTTGGACGTTGGTGCCCCAGACCAGGAATTCGGCTTCGACGTTGGCCCT
GTCTGCTTCCTGTAA
|
| Protein Properties |
|---|
| Number of Residues
| 1464 |
| Molecular Weight
| 138941.1 |
| Theoretical pI
| 5.47 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
|
| Protein Sequence
|
>Collagen alpha-1(I) chain
MFSFVDLRLLLLLAATALLTHGQEEGQVEGQDEDIPPITCVQNGLRYHDRDVWKPEPCRI
CVCDNGKVLCDDVICDETKNCPGAEVPEGECCPVCPDGSESPTDQETTGVEGPKGDTGPR
GPRGPAGPPGRDGIPGQPGLPGPPGPPGPPGPPGLGGNFAPQLSYGYDEKSTGGISVPGP
MGPSGPRGLPGPPGAPGPQGFQGPPGEPGEPGASGPMGPRGPPGPPGKNGDDGEAGKPGR
PGERGPPGPQGARGLPGTAGLPGMKGHRGFSGLDGAKGDAGPAGPKGEPGSPGENGAPGQ
MGPRGLPGERGRPGAPGPAGARGNDGATGAAGPPGPTGPAGPPGFPGAVGAKGEAGPQGP
RGSEGPQGVRGEPGPPGPAGAAGPAGNPGADGQPGAKGANGAPGIAGAPGFPGARGPSGP
QGPGGPPGPKGNSGEPGAPGSKGDTGAKGEPGPVGVQGPPGPAGEEGKRGARGEPGPTGL
PGPPGERGGPGSRGFPGADGVAGPKGPAGERGSPGPAGPKGSPGEAGRPGEAGLPGAKGL
TGSPGSPGPDGKTGPPGPAGQDGRPGPPGPPGARGQAGVMGFPGPKGAAGEPGKAGERGV
PGPPGAVGPAGKDGEAGAQGPPGPAGPAGERGEQGPAGSPGFQGLPGPAGPPGEAGKPGE
QGVPGDLGAPGPSGARGERGFPGERGVQGPPGPAGPRGANGAPGNDGAKGDAGAPGAPGS
QGAPGLQGMPGERGAAGLPGPKGDRGDAGPKGADGSPGKDGVRGLTGPIGPPGPAGAPGD
KGESGPSGPAGPTGARGAPGDRGEPGPPGPAGFAGPPGADGQPGAKGEPGDAGAKGDAGP
PGPAGPAGPPGPIGNVGAPGAKGARGSAGPPGATGFPGAAGRVGPPGPSGNAGPPGPPGP
AGKEGGKGPRGETGPAGRPGEVGPPGPPGPAGEKGSPGADGPAGAPGTPGPQGIAGQRGV
VGLPGQRGERGFPGLPGPSGEPGKQGPSGASGERGPPGPMGPPGLAGPPGESGREGAPGA
EGSPGRDGSPGAKGDRGETGPAGPPGAPGAPGAPGPVGPAGKSGDRGETGPAGPTGPVGP
VGARGPAGPQGPRGDKGETGEQGDRGIKGHRGFSGLQGPPGPPGSPGEQGPSGASGPAGP
RGPPGSAGAPGKDGLNGLPGPIGPPGPRGRTGDAGPVGPPGPPGPPGPPGPPSAGFDFSF
LPQPPQEKAHDGGRYYRADDANVVRDRDLEVDTTLKSLSQQIENIRSPEGSRKNPARTCR
DLKMCHSDWKSGEYWIDPNQGCNLDAIKVFCNMETGETCVYPTQPSVAQKNWYISKNPKD
KRHVWFGESMTDGFQFEYGGQGSDPADVAIQLTFLRLMSTEASQNITYHCKNSVAYMDQQ
TGNLKKALLLQGSNEIEIRAEGNSRFTYSVTVDGCTSHTGAWGKTVIEYKTTKTSRLPII
DVAPLDVGAPDQEFGFDVGPVCFL
|
| External Links |
|---|
| GenBank ID Protein
| 1418928 |
| UniProtKB/Swiss-Prot ID
| P02452 |
| UniProtKB/Swiss-Prot Entry Name
| CO1A1_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| Z74615 |
| GeneCard ID
| COL1A1 |
| GenAtlas ID
| COL1A1 |
| HGNC ID
| HGNC:2197 |
| References |
|---|
| General References
| Not Available |