| Identification |
|---|
| HMDB Protein ID
| CDBP01560 |
| Secondary Accession Numbers
| Not Available |
| Name
| Angiotensin-converting enzyme |
| Description
| Not Available |
| Synonyms
|
- ACE
- Angiotensin-converting enzyme, soluble form
- CD143 antigen
- Dipeptidyl carboxypeptidase I
- Kininase II
|
| Gene Name
| ACE |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in metallopeptidase activity |
| Specific Function
| Converts angiotensin I to angiotensin II by release of the terminal His-Leu, this results in an increase of the vasoconstrictor activity of angiotensin. Also able to inactivate bradykinin, a potent vasodilator. Has also a glycosidase activity which releases GPI-anchored proteins from the membrane by cleaving the mannose linkage in the GPI moiety |
| GO Classification
|
| Component |
| membrane |
| cell part |
| Function |
| hydrolase activity |
| peptidyl-dipeptidase activity |
| peptidase activity |
| peptidase activity, acting on l-amino acid peptides |
| metallopeptidase activity |
| exopeptidase activity |
| catalytic activity |
| Process |
| metabolic process |
| macromolecule metabolic process |
| protein metabolic process |
| proteolysis |
|
| Cellular Location
|
- Cell membrane
- Single-pass type I membrane protein
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Captopril Action Pathway | 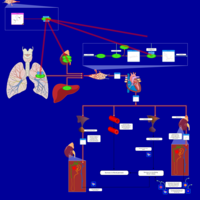 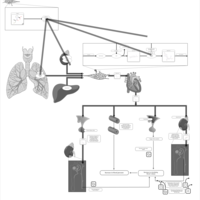  | Not Available | | Enalapril Action Pathway | 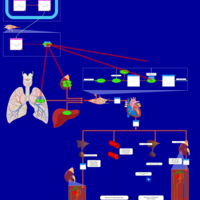 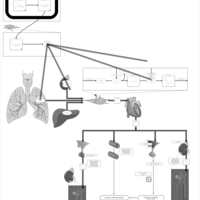  | Not Available | | Enalapril Metabolism Pathway |    | Not Available | | Benazepril Action Pathway | 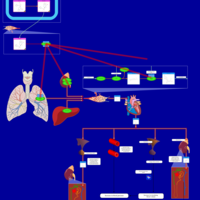 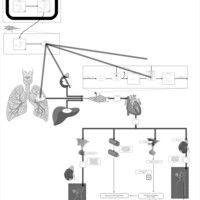  | Not Available | | Benazepril Metabolism Pathway |  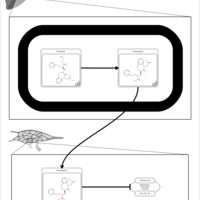  | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:1 |
| Locus
| 17q23.3 |
| SNPs
| ACE |
| Gene Sequence
|
>3921 bp
ATGGGGGCCGCCTCGGGCCGCCGGGGGCCGGGGCTGCTGCTGCCGCTGCCGCTGCTGTTG
CTGCTGCCGCCGCAGCCCGCCCTGGCGTTGGACCCCGGGCTGCAGCCCGGCAACTTTTCT
GCTGACGAGGCCGGGGCGCAGCTCTTCGCGCAGAGCTACAACTCCAGCGCCGAACAGGTG
CTGTTCCAGAGCGTGGCCGCCAGCTGGGCGCACGACACCAACATCACCGCGGAGAATGCA
AGGCGCCAGGAGGAAGCAGCCCTGCTCAGCCAGGAGTTTGCGGAGGCCTGGGGCCAGAAG
GCCAAGGAGCTGTATGAACCGATCTGGCAGAACTTCACGGACCCGCAGCTGCGCAGGATC
ATCGGAGCTGTGCGAACCCTGGGCTCTGCCAACCTGCCCCTGGCTAAGCGGCAGCAGTAC
AACGCCCTGCTAAGCAACATGAGCAGGATCTACTCCACCGCCAAGGTCTGCCTCCCCAAC
AAGACTGCCACCTGCTGGTCCCTGGACCCAGATCTCACCAACATCCTGGCTTCCTCGCGA
AGCTACGCCATGCTCCTGTTTGCCTGGGAGGGCTGGCACAACGCTGCGGGCATCCCGCTG
AAACCGCTGTACGAGGATTTCACTGCCCTCAGCAATGAAGCCTACAAGCAGGACGGCTTC
ACAGACACGGGGGCCTACTGGCGCTCCTGGTACAACTCCCCCACCTTCGAGGACGATCTG
GAACACCTCTACCAACAGCTAGAGCCCCTCTACCTGAACCTCCATGCCTTCGTCCGCCGC
GCACTGCATCGCCGATACGGAGACAGATACATCAACCTCAGGGGACCCATCCCTGCTCAT
CTGCTGGGAGACATGTGGGCCCAGAGCTGGGAAAACATCTACGACATGGTGGTGCCTTTC
CCAGACAAGCCCAACCTCGATGTCACCAGTACTATGCTGCAGCAGGGCTGGAACGCCACG
CACATGTTCCGGGTGGCAGAGGAGTTCTTCACCTCCCTGGAGCTCTCCCCCATGCCTCCC
GAGTTCTGGGAAGGGTCGATGCTGGAGAAGCCGGCCGACGGGCGGGAAGTGGTGTGCCAC
GCCTCGGCTTGGGACTTCTACAACAGGAAAGACTTCAGGATCAAGCAGTGCACACGGGTC
ACGATGGACCAGCTCTCCACAGTGCACCATGAGATGGGCCATATACAGTACTACCTGCAG
TACAAGGATCTGCCCGTCTCCCTGCGTCGGGGGGCCAACCCCGGCTTCCATGAGGCCATT
GGGGACGTGCTGGCGCTCTCGGTCTCCACTCCTGAACATCTGCACAAAATCGGCCTGCTG
GACCGTGTCACCAATGACACGGAAAGTGACATCAATTACTTGCTAAAAATGGCACTGGAA
AAAATTGCCTTCCTGCCCTTTGGCTACTTGGTGGACCAGTGGCGCTGGGGGGTCTTTAGT
GGGCGTACCCCCCCTTCCCGCTACAACTTCGACTGGTGGTATCTTCGAACCAAGTATCAG
GGGATCTGTCCTCCTGTTACCCGAAACGAAACCCACTTTGATGCTGGAGCTAAGTTTCAT
GTTCCAAATGTGACACCATACATCAGGTACTTTGTGAGTTTTGTCCTGCAGTTCCAGTTC
CATGAAGCCCTGTGCAAGGAGGCAGGCTATGAGGGCCCACTGCACCAGTGTGACATCTAC
CGGTCCACCAAGGCAGGGGCCAAGCTCCGGAAGGTGCTGCAGGCTGGCTCCTCCAGGCCC
TGGCAGGAGGTGCTGAAGGACATGGTCGGCTTAGATGCCCTGGATGCCCAGCCGCTGCTC
AAGTACTTCCAGCCAGTCACCCAGTGGCTGCAGGAGCAGAACCAGCAGAACGGCGAGGTC
CTGGGCTGGCCCGAGTACCAGTGGCACCCGCCGTTGCCTGACAACTACCCGGAGGGCATA
GACCTGGTGACTGATGAGGCTGAGGCCAGCAAGTTTGTGGAGGAATATGACCGGACATCC
CAGGTGGTGTGGAACGAGTATGCCGAGGCCAACTGGAACTACAACACCAACATCACCACA
GAGACCAGCAAGATTCTGCTGCAGAAGAACATGCAAATAGCCAACCACACCCTGAAGTAC
GGCACCCAGGCCAGGAAGTTTGATGTGAACCAGTTGCAGAACACCACTATCAAGCGGATC
ATAAAGAAGGTTCAGGACCTAGAACGGGCAGCGCTGCCTGCCCAGGAGCTGGAGGAGTAC
AACAAGATCCTGTTGGATATGGAAACCACCTACAGCGTGGCCACTGTGTGCCACCCGAAT
GGCAGCTGCCTGCAGCTCGAGCCAGATCTGACGAATGTGATGGCCACATCCCGGAAATAT
GAAGACCTGTTATGGGCATGGGAGGGCTGGCGAGACAAGGCGGGGAGAGCCATCCTCCAG
TTTTACCCGAAATACGTGGAACTCATCAACCAGGCTGCCCGGCTCAATGGCTATGTAGAT
GCAGGGGACTCGTGGAGGTCTATGTACGAGACACCATCCCTGGAGCAAGACCTGGAGCGG
CTCTTCCAGGAGCTGCAGCCACTCTACCTCAACCTGCATGCCTACGTGCGCCGGGCCCTG
CACCGTCACTACGGGGCCCAGCACATCAACCTGGAGGGGCCCATTCCTGCTCACCTGCTG
GGGAACATGTGGGCGCAGACCTGGTCCAACATCTATGACTTGGTGGTGCCCTTCCCTTCA
GCCCCCTCGATGGACACCACAGAGGCTATGCTAAAGCAGGGCTGGACGCCCAGGAGGATG
TTTAAGGAGGCTGATGATTTCTTCACCTCCCTGGGGCTGCTGCCCGTGCCTCCTGAGTTC
TGGAACAAGTCGATGCTGGAGAAGCCAACCGACGGGCGGGAGGTGGTCTGCCACGCCTCG
GCCTGGGACTTCTACAACGGCAAGGACTTCCGGATCAAGCAGTGCACCACCGTGAACTTG
GAGGACCTGGTGGTGGCCCACCACGAAATGGGCCACATCCAGTATTTCATGCAGTACAAA
GACTTACCTGTGGCCTTGAGGGAGGGTGCCAACCCCGGCTTCCATGAGGCCATTGGGGAC
GTGCTAGCCCTCTCAGTGTCTACGCCCAAGCACCTGCACAGTCTCAACCTGCTGAGCAGT
GAGGGTGGCAGCGACGAGCATGACATCAACTTTCTGATGAAGATGGCCCTTGACAAGATC
GCCTTTATCCCCTTCAGCTACCTCGTCGATCAGTGGCGCTGGAGGGTATTTGATGGAAGC
ATCACCAAGGAGAACTATAACCAGGAGTGGTGGAGCCTCAGGCTGAAGTACCAGGGCCTC
TGCCCCCCAGTGCCCAGGACTCAAGGTGACTTTGACCCAGGGGCCAAGTTCCACATTCCT
TCTAGCGTGCCTTACATCAGGTACTTTGTCAGCTTCATCATCCAGTTCCAGTTCCACGAG
GCACTGTGCCAGGCAGCTGGCCACACGGGCCCCCTGCACAAGTGTGACATCTACCAGTCC
AAGGAGGCCGGGCAGCGCCTGGCGACCGCCATGAAGCTGGGCTTCAGTAGGCCGTGGCCG
GAAGCCATGCAGCTGATCACGGGCCAGCCCAACATGAGCGCCTCGGCCATGTTGAGCTAC
TTCAAGCCGCTGCTGGACTGGCTCCGCACGGAGAACGAGCTGCATGGGGAGAAGCTGGGC
TGGCCGCAGTACAACTGGACGCCGAACTCCGCTCGCTCAGAAGGGCCCCTCCCAGACAGC
GGCCGCGTCAGCTTCCTGGGCCTGGACCTGGATGCGCAGCAGGCCCGCGTGGGCCAGTGG
CTGCTGCTCTTCCTGGGCATCGCCCTGCTGGTAGCCACCCTGGGCCTCAGCCAGCGGCTC
TTCAGCATCCGCCACCGCAGCCTCCACCGGCACTCCCACGGGCCCCAGTTCGGCTCCGAG
GTGGAGCTGAGACACTCCTGA
|
| Protein Properties |
|---|
| Number of Residues
| 1306 |
| Molecular Weight
| 149713.7 |
| Theoretical pI
| 6.36 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
|
| Protein Sequence
|
>Angiotensin-converting enzyme
MGAASGRRGPGLLLPLPLLLLLPPQPALALDPGLQPGNFSADEAGAQLFAQSYNSSAEQV
LFQSVAASWAHDTNITAENARRQEEAALLSQEFAEAWGQKAKELYEPIWQNFTDPQLRRI
IGAVRTLGSANLPLAKRQQYNALLSNMSRIYSTAKVCLPNKTATCWSLDPDLTNILASSR
SYAMLLFAWEGWHNAAGIPLKPLYEDFTALSNEAYKQDGFTDTGAYWRSWYNSPTFEDDL
EHLYQQLEPLYLNLHAFVRRALHRRYGDRYINLRGPIPAHLLGDMWAQSWENIYDMVVPF
PDKPNLDVTSTMLQQGWNATHMFRVAEEFFTSLELSPMPPEFWEGSMLEKPADGREVVCH
ASAWDFYNRKDFRIKQCTRVTMDQLSTVHHEMGHIQYYLQYKDLPVSLRRGANPGFHEAI
GDVLALSVSTPEHLHKIGLLDRVTNDTESDINYLLKMALEKIAFLPFGYLVDQWRWGVFS
GRTPPSRYNFDWWYLRTKYQGICPPVTRNETHFDAGAKFHVPNVTPYIRYFVSFVLQFQF
HEALCKEAGYEGPLHQCDIYRSTKAGAKLRKVLQAGSSRPWQEVLKDMVGLDALDAQPLL
KYFQPVTQWLQEQNQQNGEVLGWPEYQWHPPLPDNYPEGIDLVTDEAEASKFVEEYDRTS
QVVWNEYAEANWNYNTNITTETSKILLQKNMQIANHTLKYGTQARKFDVNQLQNTTIKRI
IKKVQDLERAALPAQELEEYNKILLDMETTYSVATVCHPNGSCLQLEPDLTNVMATSRKY
EDLLWAWEGWRDKAGRAILQFYPKYVELINQAARLNGYVDAGDSWRSMYETPSLEQDLER
LFQELQPLYLNLHAYVRRALHRHYGAQHINLEGPIPAHLLGNMWAQTWSNIYDLVVPFPS
APSMDTTEAMLKQGWTPRRMFKEADDFFTSLGLLPVPPEFWNKSMLEKPTDGREVVCHAS
AWDFYNGKDFRIKQCTTVNLEDLVVAHHEMGHIQYFMQYKDLPVALREGANPGFHEAIGD
VLALSVSTPKHLHSLNLLSSEGGSDEHDINFLMKMALDKIAFIPFSYLVDQWRWRVFDGS
ITKENYNQEWWSLRLKYQGLCPPVPRTQGDFDPGAKFHIPSSVPYIRYFVSFIIQFQFHE
ALCQAAGHTGPLHKCDIYQSKEAGQRLATAMKLGFSRPWPEAMQLITGQPNMSASAMLSY
FKPLLDWLRTENELHGEKLGWPQYNWTPNSARSEGPLPDSGRVSFLGLDLDAQQARVGQW
LLLFLGIALLVATLGLSQRLFSIRHRSLHRHSHGPQFGSEVELRHS
|
| External Links |
|---|
| GenBank ID Protein
| Not Available |
| UniProtKB/Swiss-Prot ID
| P12821 |
| UniProtKB/Swiss-Prot Entry Name
| ACE_HUMAN |
| PDB IDs
|
|
| GenBank Gene ID
| J04144 |
| GeneCard ID
| ACE |
| GenAtlas ID
| ACE |
| HGNC ID
| HGNC:2707 |
| References |
|---|
| General References
| Not Available |