| Identification |
|---|
| HMDB Protein ID
| CDBP01067 |
| Secondary Accession Numbers
| Not Available |
| Name
| Mitogen-activated protein kinase kinase kinase 1 |
| Description
| Not Available |
| Synonyms
|
- MAPK/ERK kinase kinase 1
- MEK kinase 1
- MEKK 1
|
| Gene Name
| MAP3K1 |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in magnesium ion binding |
| Specific Function
| Component of a protein kinase signal transduction cascade. Activates the ERK and JNK kinase pathways by phosphorylation of MAP2K1 and MAP2K4. Activates CHUK and IKBKB, the central protein kinases of the NF-kappa-B pathway |
| GO Classification
|
| Function |
| transferase activity, transferring phosphorus-containing groups |
| kinase activity |
| nucleoside binding |
| purine nucleoside binding |
| adenyl nucleotide binding |
| adenyl ribonucleotide binding |
| atp binding |
| magnesium ion binding |
| protein binding |
| ion binding |
| protein kinase activity |
| cation binding |
| protein serine/threonine kinase activity |
| metal ion binding |
| receptor signaling protein serine/threonine kinase activity |
| binding |
| map kinase kinase kinase activity |
| catalytic activity |
| transition metal ion binding |
| zinc ion binding |
| transferase activity |
| Process |
| signaling process |
| signal transmission |
| cellular metabolic process |
| protein amino acid phosphorylation |
| phosphorylation |
| signal transmission via phosphorylation event |
| intracellular protein kinase cascade |
| mapkkk cascade |
| phosphorus metabolic process |
| phosphate metabolic process |
| metabolic process |
|
| Cellular Location
|
Not Available
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Intracellular Signalling Through Adenosine Receptor A2a and Adenosine | 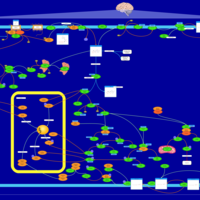   | Not Available | | Intracellular Signalling Through Adenosine Receptor A2b and Adenosine | 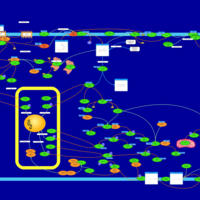   | Not Available |
|
| Gene Properties |
|---|
| Chromosome Location
| Chromosome:5 |
| Locus
| 5q11.2 |
| SNPs
| MAP3K1 |
| Gene Sequence
|
>4539 bp
ATGGCGGCGGCGGCGGGGAATCGCGCCTCGTCGTCGGGATTCCCGGGCGCCAGGGCTACG
AGCCCTGAGGCAGGCGGCGGCGGAGGAGCCCTCAAGGCGAGCAGCGCGCCCGCGGCTGCC
GCGGGACTGCTGCGGGAGGCGGGCAGCGGGGGCCGCGAGCGGGCGGACTGGCGGCGGCGG
CAGCTGCGCAAAGTGCGGAGTGTGGAGCTGGACCAGCTGCCTGAGCAGCCGCTCTTCCTT
GCCGCCTCACCGCCGGCCTCCTCGACTTCCCCGTCGCCGGAGCCCGCGGACGCAGCGGGG
AGTGGGACCGGCTTCCAGCCTGTGGCGGTGCCGCCGCCCCACGGAGCCGCGAGCCGCGGC
GGCGCCCACCTTACCGAGTCGGTGGCGGCGCCGGACAGCGGCGCCTCGAGTCCCGCAGCG
GCCGAGCCCGGGGAGAAGCGGGCGCCCGCCGCCGAGCCGTCTCCTGCAGCGGCCCCCGCC
GGTCGTGAGATGGAGAATAAAGAAACTCTCAAAGGGTTGCACAAGATGGATGATCGTCCA
GAGGAACGAATGATCAGGGAGAAACTGAAGGCAACCTGTATGCCAGCCTGGAAGCACGAA
TGGTTGGAAAGGAGAAATAGGCGAGGGCCTGTGGTGGTAAAACCAATCCCAGTTAAAGGA
GATGGATCTGAAATGAATCACTTAGCAGCTGAGTCTCCAGGAGAGGTCCAGGCAAGTGCG
GCTTCACCAGCTTCCAAAGGCCGACGCAGTCCTTCTCCTGGCAACTCCCCATCAGGTCGC
ACAGTGAAATCAGAATCTCCAGGAGTAAGGAGAAAAAGAGTTTCCCCAGTGCCTTTTCAG
AGTGGCAGAATCACACCACCCCGAAGAGCCCCTTCACCAGATGGCTTCTCACCATATAGC
CCTGAGGAAACAAACCGCCGTGTTAACAAAGTGATGCGGGCCAGACTGTACTTACTGCAG
CAGATAGGGCCTAACTCTTTCCTGATTGGAGGAGACAGCCCAGACAATAAATACCGGGTG
TTTATTGGGCCTCAGAACTGCAGCTGTGCACGTGGAACATTCTGTATTCATCTGCTATTT
GTGATGCTCCGGGTGTTTCAACTAGAACCTTCAGACCCAATGTTATGGAGAAAAACTTTA
AAGAATTTTGAGGTTGAGAGTTTGTTCCAGAAATATCACAGTAGGCGTAGCTCAAGGATC
AAAGCTCCATCTCGTAACACCATCCAGAAGTTTGTTTCACGCATGTCAAATTCTCATACA
TTGTCATCATCTAGTACTTCTACGTCTAGTTCAGAAAACAGCATAAAGGATGAAGAGGAA
CAGATGTGTCCTATTTGCTTGTTGGGCATGCTTGATGAAGAAAGTCTTACAGTGTGTGAA
GACGGCTGCAGGAACAAGCTGCACCACCACTGCATGTCAATTTGGGCAGAAGAGTGTAGA
AGAAATAGAGAACCTTTAATATGTCCCCTTTGTAGATCTAAGTGGAGATCTCATGATTTC
TACAGCCACGAGTTGTCAAGTCCTGTGGATTCCCCTTCTTCCCTCAGAGCTGCACAGCAG
CAAACCGTACAGCAGCAGCCTTTGGCTGGATCACGAAGGAATCAAGAGAGCAATTTTAAC
CTTACTCATTATGGAACTCAGCAAATCCCTCCTGCTTACAAAGATTTAGCTGAGCCATGG
ATTCAGGTGTTTGGAATGGAACTCGTTGGCTGCTTATTTTCTAGAAACTGGAATGTGAGA
GAGATGGCCCTCAGGCGTCTTTCCCATGATGTCAGTGGGGCCCTGCTGTTGGCAAATGGG
GAGAGCACTGGAAATTCTGGGGGCAGCAGTGGAAGCAGCCCGAGTGGGGGAGCCACCAGT
GGGTCTTCCCAGACCAGTATCTCAGGAGATGTGGTGGAGGCATGCTGCAGCGTTCTGTCA
ATGGTCTGTGCTGACCCTGTCTACAAAGTGTACGTTGCTGCTTTAAAAACATTGAGAGCC
ATGCTGGTATATACTCCTTGCCACAGTTTAGCGGAAAGAATCAAACTTCAGAGACTTCTC
CAGCCAGTTGTAGACACCATCCTAGTCAAATGTGCAGATGCCAATAGCCGCACAAGTCAG
CTGTCCATATCAACACTGTTGGAACTGTGCAAAGGCCAAGCAGGAGAGTTGGCAGTTGGC
AGAGAAATACTAAAAGCTGGATCCATTGGTATTGGTGGTGTTGATTATGTCTTAAATTGT
ATTCTTGGAAACCAAACTGAATCAAACAATTGGCAAGAACTTCTTGGCCGCCTTTGTCTT
ATAGATAGACTGTTGTTGGAATTTCCTGCTGAATTTTATCCTCATATTGTCAGTACTGAT
GTTTCACAAGCTGAGCCTGTTGAAATCAGGTATAAGAAGCTGCTGTCCCTCTTAACCTTT
GCTTTGCAGTCCATTGATAATTCCCACTCAATGGTTGGCAAACTTTCCAGAAGGATCTAC
TTGAGTTCTGCAAGAATGGTTACTACAGTACCCCATGTGTTTTCAAAACTGTTAGAAATG
CTGAGTGTTTCCAGTTCCACTCACTTCACCAGGATGCGTCGCCGTTTGATGGCTATTGCA
GATGAGGTGGAAATTGCCGAAGCCATCCAGTTGGGCGTAGAAGACACTTTGGATGGTCAA
CAGGACAGCTTCTTGCAGGCATCTGTTCCCAACAACTATCTGGAAACCACAGAGAACAGT
TCCCCTGAGTGCACAGTCCATTTAGAGAAAACTGGAAAAGGATTATGTGCTACAAAATTG
AGTGCCAGTTCAGAGGACATTTCTGAGAGACTGGCCAGCATTTCAGTAGGACCTTCTAGT
TCAACAACAACAACAACAACAACAACAGAGCAACCAAAGCCAATGGTTCAAACAAAAGGC
AGACCCCACAGTCAGTGTTTGAACTCCTCTCCTTTATCTCATCATTCCCAATTAATGTTT
CCAGCCTTGTCAACCCCTTCTTCTTCTACCCCATCTGTACCAGCTGGCACTGCAACAGAT
GTCTCTAAGCATAGACTTCAGGGATTCATTCCCTGCAGAATACCTTCTGCATCTCCTCAA
ACACAGCGCAAGTTTTCTCTACAATTCCACAGAAACTGTCCTGAAAACAAAGACTCAGAT
AAACTTTCCCCAGTCTTTACTCAGTCAAGACCCTTGCCCTCCAGTAACATACACAGGCCA
AAGCCATCTAGACCTACCCCAGGTAATACAAGTAAACAGGGAGATCCCTCAAAAAATAGC
ATGACACTTGATCTGAACAGTAGTTCCAAATGTGATGACAGCTTTGGCTGTAGCAGCAAT
AGTAGTAATGCTGTTATACCCAGTGACGAGACAGTGTTCACCCCAGTAGAGGAGAAATGC
AGATTAGATGTCAATACAGAGCTCAACTCCAGTATTGAGGACCTTCTTGAAGCATCTATG
CCTTCAAGTGATACAACAGTAACTTTTAAGTCAGAAGTTGCTGTCCTGTCTCCTGAAAAG
GCTGAAAATGATGATACCTACAAAGATGATGTGAATCATAATCAAAAGTGCAAAGAGAAG
ATGGAAGCTGAAGAAGAAGAAGCTTTAGCAATTGCCATGGCAATGTCAGCGTCTCAGGAT
GCCCTCCCCATAGTTCCTCAGCTGCAGGTTGAAAATGGAGAAGATATCATCATTATTCAA
CAGGATACACCAGAGACTCTACCAGGACATACCAAAGCAAAACAACCGTATAGAGAAGAC
ACTGAATGGCTGAAAGGTCAACAGATAGGCCTTGGAGCATTTTCTTCTTGTTATCAGGCT
CAAGATGTGGGAACTGGAACTTTAATGGCTGTTAAACAGGTGACTTATGTCAGAAACACA
TCTTCTGAGCAAGAAGAAGTAGTAGAAGCACTAAGAGAAGAGATAAGAATGATGAGCCAT
CTGAATCATCCAAACATCATTAGGATGTTGGGAGCCACGTGTGAGAAGAGCAATTACAAT
CTCTTCATTGAATGGATGGCAGGGGGATCGGTGGCTCATTTGCTGAGTAAATATGGAGCC
TTCAAAGAATCAGTAGTTATTAACTACACTGAACAGTTACTCCGTGGCCTTTCGTATCTC
CATGAAAACCAAATCATTCACAGAGATGTCAAAGGTGCCAATTTGCTAATTGACAGCACT
GGTCAGAGACTAAGAATTGCAGATTTTGGAGCTGCAGCCAGGTTGGCATCAAAAGGAACT
GGTGCAGGAGAGTTTCAGGGACAATTACTGGGGACAATTGCATTTATGGCACCTGAGGTA
CTAAGAGGTCAACAGTATGGAAGGAGCTGTGATGTATGGAGTGTTGGCTGTGCTATTATA
GAAATGGCTTGTGCAAAACCACCATGGAATGCAGAAAAACACTCCAATCATCTTGCTTTG
ATATTTAAGATTGCTAGTGCAACTACTGCTCCATCGATCCCTTCACATTTGTCTCCTGGT
TTACGAGATGTGGCTCTTCGTTGTTTAGAACTTCAACCTCAGGACAGACCTCCATCAAGA
GAGCTACTGAAGCATCCAGTCTTTCGTACTACATGGTAG
|
| Protein Properties |
|---|
| Number of Residues
| 1512 |
| Molecular Weight
| 164468.3 |
| Theoretical pI
| 7.77 |
| Pfam Domain Function
|
|
| Signals
|
|
|
Transmembrane Regions
|
|
| Protein Sequence
|
>Mitogen-activated protein kinase kinase kinase 1
MAAAAGNRASSSGFPGARATSPEAGGGGGALKASSAPAAAAGLLREAGSGGRERADWRRR
QLRKVRSVELDQLPEQPLFLAASPPASSTSPSPEPADAAGSGTGFQPVAVPPPHGAASRG
GAHLTESVAAPDSGASSPAAAEPGEKRAPAAEPSPAAAPAGREMENKETLKGLHKMDDRP
EERMIREKLKATCMPAWKHEWLERRNRRGPVVVKPIPVKGDGSEMNHLAAESPGEVQASA
ASPASKGRRSPSPGNSPSGRTVKSESPGVRRKRVSPVPFQSGRITPPRRAPSPDGFSPYS
PEETNRRVNKVMRARLYLLQQIGPNSFLIGGDSPDNKYRVFIGPQNCSCARGTFCIHLLF
VMLRVFQLEPSDPMLWRKTLKNFEVESLFQKYHSRRSSRIKAPSRNTIQKFVSRMSNSHT
LSSSSTSTSSSENSIKDEEEQMCPICLLGMLDEESLTVCEDGCRNKLHHHCMSIWAEECR
RNREPLICPLCRSKWRSHDFYSHELSSPVDSPSSLRAAQQQTVQQQPLAGSRRNQESNFN
LTHYGTQQIPPAYKDLAEPWIQVFGMELVGCLFSRNWNVREMALRRLSHDVSGALLLANG
ESTGNSGGSSGSSPSGGATSGSSQTSISGDVVEACCSVLSMVCADPVYKVYVAALKTLRA
MLVYTPCHSLAERIKLQRLLQPVVDTILVKCADANSRTSQLSISTLLELCKGQAGELAVG
REILKAGSIGIGGVDYVLNCILGNQTESNNWQELLGRLCLIDRLLLEFPAEFYPHIVSTD
VSQAEPVEIRYKKLLSLLTFALQSIDNSHSMVGKLSRRIYLSSARMVTTVPHVFSKLLEM
LSVSSSTHFTRMRRRLMAIADEVEIAEAIQLGVEDTLDGQQDSFLQASVPNNYLETTENS
SPECTVHLEKTGKGLCATKLSASSEDISERLASISVGPSSSTTTTTTTTEQPKPMVQTKG
RPHSQCLNSSPLSHHSQLMFPALSTPSSSTPSVPAGTATDVSKHRLQGFIPCRIPSASPQ
TQRKFSLQFHRNCPENKDSDKLSPVFTQSRPLPSSNIHRPKPSRPTPGNTSKQGDPSKNS
MTLDLNSSSKCDDSFGCSSNSSNAVIPSDETVFTPVEEKCRLDVNTELNSSIEDLLEASM
PSSDTTVTFKSEVAVLSPEKAENDDTYKDDVNHNQKCKEKMEAEEEEALAIAMAMSASQD
ALPIVPQLQVENGEDIIIIQQDTPETLPGHTKAKQPYREDTEWLKGQQIGLGAFSSCYQA
QDVGTGTLMAVKQVTYVRNTSSEQEEVVEALREEIRMMSHLNHPNIIRMLGATCEKSNYN
LFIEWMAGGSVAHLLSKYGAFKESVVINYTEQLLRGLSYLHENQIIHRDVKGANLLIDST
GQRLRIADFGAAARLASKGTGAGEFQGQLLGTIAFMAPEVLRGQQYGRSCDVWSVGCAII
EMACAKPPWNAEKHSNHLALIFKIASATTAPSIPSHLSPGLRDVALRCLELQPQDRPPSR
ELLKHPVFRTTW
|
| External Links |
|---|
| GenBank ID Protein
| 153945765 |
| UniProtKB/Swiss-Prot ID
| Q13233 |
| UniProtKB/Swiss-Prot Entry Name
| M3K1_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| NM_005921.1 |
| GeneCard ID
| MAP3K1 |
| GenAtlas ID
| MAP3K1 |
| HGNC ID
| HGNC:6848 |
| References |
|---|
| General References
| Not Available |