| Identification |
|---|
| HMDB Protein ID
| CDBP00901 |
| Secondary Accession Numbers
| Not Available |
| Name
| DNA polymerase epsilon catalytic subunit A |
| Description
| Not Available |
| Synonyms
|
- DNA polymerase II subunit A
|
| Gene Name
| POLE |
| Protein Type
| Enzyme |
| Biological Properties |
|---|
| General Function
| Involved in nucleotide binding |
| Specific Function
| Participates in DNA repair and in chromosomal DNA replication.
|
| GO Classification
|
| Biological Process |
| transcription-coupled nucleotide-excision repair |
| S phase of mitotic cell cycle |
| G1/S transition of mitotic cell cycle |
| in utero embryonic development |
| base-excision repair, gap-filling |
| DNA synthesis involved in DNA repair |
| DNA replication initiation |
| M/G1 transition of mitotic cell cycle |
| telomere maintenance via recombination |
| telomere maintenance via semi-conservative replication |
| nucleotide-excision repair, DNA gap filling |
| Cellular Component |
| nucleoplasm |
| epsilon DNA polymerase complex |
| Component |
| organelle |
| membrane-bounded organelle |
| intracellular membrane-bounded organelle |
| nucleus |
| Function |
| metal ion binding |
| binding |
| nucleotide binding |
| catalytic activity |
| transition metal ion binding |
| zinc ion binding |
| transferase activity |
| transferase activity, transferring phosphorus-containing groups |
| nucleotidyltransferase activity |
| dna polymerase activity |
| dna-directed dna polymerase activity |
| nucleic acid binding |
| dna binding |
| ion binding |
| cation binding |
| Molecular Function |
| zinc ion binding |
| chromatin binding |
| DNA binding |
| nucleotide binding |
| metal ion binding |
| 4 iron, 4 sulfur cluster binding |
| DNA-directed DNA polymerase activity |
| Process |
| metabolic process |
| macromolecule metabolic process |
| cellular macromolecule metabolic process |
| dna metabolic process |
| dna replication |
|
| Cellular Location
|
- Nucleus
|
| Pathways
|
| Name | SMPDB/Pathwhiz | KEGG | | Nucleotide Excision Repair | 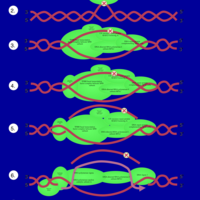 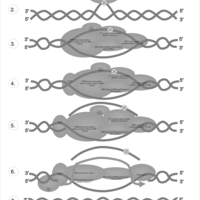  | Not Available | | DNA replication | Not Available | 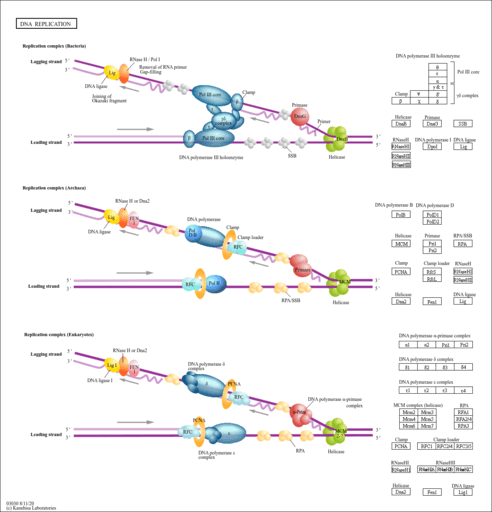 | | Base excision repair | Not Available | 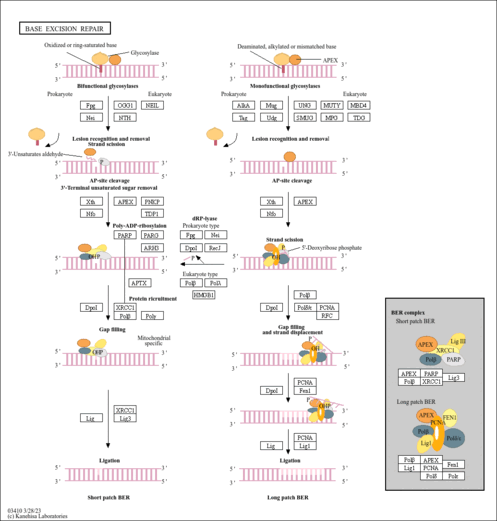 | | HTLV-I infection | Not Available |  |
|
| Gene Properties |
|---|
| Chromosome Location
| 12 |
| Locus
| 12q24.3 |
| SNPs
| POLE |
| Gene Sequence
|
>6861 bp
ATGTCTCTGAGGAGCGGCGGGCGGCGGCGCGCGGACCCAGGCGCGGATGGCGAGGCCAGC
AGGGATGATGGCGCCACTTCCTCAGTTTCGGCACTCAAGCGCCTGGAACGGAGTCAGTGG
ACGGATAAGATGGATTTGCGGTTTGGTTTTGAGCGGCTGAAGGAGCCTGGTGAGAAGACA
GGCTGGCTCATTAACATGCATCCTACCGAGATTTTAGATGAAGATAAGCGCTTAGGCAGT
GCAGTGGATTACTACTTTATTCAAGATGACGGAAGCAGATTTAAGGTGGCTTTGCCCTAT
AAACCGTATTTCTACATTGCGACCAGAAAGGGTTGTGAGCGAGAAGTTTCATCTTTTCTC
TCCAAGAAGTTTCAGGGCAAAATTGCAAAAGTGGAGACTGTCCCCAAAGAGGATCTGGAC
TTGCCAAATCACTTGGTGGGTTTGAAGCGAAATTACATCAGGCTGTCCTTCCACACTGTG
GAGGATCTTGTCAAAGTGAGGAAGGAGATCTCCCCTGCCGTGAAGAAGAACAGGGAGCAG
GATCACGCCAGCGACGCGTACACAGCTCTGCTTTCCAGTGTTCTGCAGAGGGGCGGTGTC
ATTACTGATGAAGAGGAAACCTCTAAGAAGATAGCTGACCAGTTGGACAACATTGTGGAC
ATGCGCGAGTACGATGTTCCCTACCACATCCGCCTCTCCATTGACCTGAAGATCCACGTG
GCTCATTGGTACAATGTCAGATACCGAGGAAATGCTTTTCCGGTAGAAATCACCCGCCGA
GATGACCTTGTTGAACGACCTGACCCTGTGGTTTTGGCATTTGACATTGAGACGACCAAA
CTGCCCCTCAAGTTTCCTGATGCTGAGACAGACCAGATTATGATGATTTCCTACATGATC
GATGGCCAGGGCTACCTCATCACCAACAGGGAGATTGTTTCAGAAGATATTGAAGATTTT
GAGTTCACCCCCAAGCCAGAATATGAAGGCCCCTTTTGTGTCTTCAATGAACCCGATGAG
GCTCATCTGATCCAAAGGTGGTTTGAACACGTCCAGGAGACCAAACCCACCATCATGGTC
ACCTACAACGGGGACTTTTTTGACTGGCCATTTGTGGAGGCCCGGGCAGCAGTCCACGGT
CTGAGCATGCAGCAGGAGATAGGCTTCCAGAAGGACAGCCAGGGGGAGTACAAGGCGCCC
CAGTGCATCCACATGGACTGCCTCAGGTGGGTGAAGAGGGACAGTTACCTTCCTGTGGGC
AGTCATAATCTCAAGGCGGCCGCCAAGGCCAAGCTAGGCTATGATCCCGTGGAGCTAGAC
CCGGAGGACATGTGCCGGATGGCCACGGAGCAGCCCCAGACTCTGGCCACGTATTCTGTG
TCAGATGCTGTCGCCACTTACTACCTGTACATGAAGTACGTCCACCCATTCATCTTTGCT
CTGTGCACCATTATTCCCATGGAGCCCGACGAGGTGCTGCGGAAGGGCTCTGGCACTCTG
TGTGAGGCCTTGCTGATGGTGCAGGCCTTCCACGCCAACATCATCTTCCCCAACAAGCAA
GAGCAGGAGTTCAATAAGCTGACGGACGACGGACACGTGCTGGACTCTGAGACCTACGTC
GGGGGCCACGTGGAGGCCCTCGAGTCTGGGGTTTTCCGCAGCGATATCCCTTGCCGGTTT
AGGATGAATCCTGCCGCCTTTGACTTCCTGCTGCAGCGGGTTGAGAAGACCTTGCGCCAC
GCCCTTGAGGAAGAGGAGAAAGTGCCTGTGGAGCAAGTCACCAACTTTGAAGAGGTGTGT
GATGAGATTAAGAGCAAGCTTGCCTCCCTGAAGGACGTTCCCAGCCGCATCGAGTGTCCA
CTCATCTACCACCTGGACGTGGGGGCCATGTACCCCAACATCATCCTGACCAACCGCCTG
CAGCCCTCTGCCATGGTGGACGAAGCCACCTGTGCTGCCTGTGACTTCAATAAGCCTGGA
GCAAACTGCCAGCGGAAGATGGCCTGGCAGTGGAGGGGCGAGTTCATGCCAGCCAGTCGC
AGCGAATACCATCGGATCCAGCACCAGCTGGAGTCAGAGAAGTTCCCCCCCTTGTTCCCA
GAGGGGCCAGCTCGGGCCTTTCATGAACTGTCCCGCGAGGAACAGGCGAAATACGAGAAG
AGAAGGCTGGCGGATTACTGCCGGAAAGCCTACAAGAAGATCCACATCACCAAGGTGGAA
GAGCGTCTCACCACCATCTGCCAGCGGGAAAACTCCTTCTACGTGGACACCGTGCGTGCC
TTCCGGGACAGGCGTTACGAGTTCAAAGGGCTCCACAAGGTGTGGAAAAAGAAGCTCTCG
GCGGCCGTGGAGGTGGGCGACGCGGCTGAGGTGAAGCGCTGCAAGAACATGGAGGTGCTG
TATGACTCGCTGCAGCTGGCCCACAAGTGCATCCTGAACTCCTTCTATGGCTATGTCATG
CGCAAGGGGGCTCGCTGGTACTCCATGGAGATGGCTGGCATCGTCTGCTTCACAGGGGCC
AACATCATCACCCAGGCACGGGAGCTGATCGAGCAGATTGGGAGGCCCTTAGAGCTGGAC
ACAGATGGTATATGGTGCGTCCTGCCCAACAGCTTCCCAGAAAATTTTGTCTTCAAGACG
ACCAATGTGAAGAAGCCCAAAGTGACCATCTCCTACCCAGGCGCCATGTTGAACATCATG
GTCAAGGAAGGCTTCACCAATGACCAGTACCAGGAGCTGGCTGAGCCGTCCTCACTCACC
TACGTCACCCGCTCAGAGAACAGCATCTTTTTTGAGGTTGATGGGCCCTACCTTGCCATG
ATTCTTCCAGCCTCCAAGGAAGAAGGCAAGAAATTGAAGAAGAGGTATGCTGTGTTCAAT
GAAGACGGTTCTCTGGCTGAGCTCAAGGGCTTTGAGGTCAAACGCCGCGGGGAACTGCAG
CTGATTAAGATCTTCCAATCCTCGGTGTTTGAGGCCTTCCTCAAGGGCAGCACGCTGGAA
GAGGTGTATGGCTCTGTAGCCAAGGTGGCTGACTACTGGCTGGACGTGCTGTACAGCAAG
GCAGCCAACATGCCTGACTCTGAGCTATTCGAGCTCATCTCTGAGAACCGTTCCATGTCT
CGGAAGCTGGAAGATTACGGGGAGCAGAAGTCTACGTCCATCAGCACAGCAAAGCGCCTG
GCCGAGTTCCTGGGAGACCAGATGGTCAAGGATGCAGGGCTGAGTTGCCGCTACATCATC
TCCCGCAAGCCCGAGGGCTCCCCTGTCACGGAGAGGGCCATCCCACTTGCCATTTTCCAA
GCAGAGCCCACGGTGAGGAAGCACTTTCTCCGGAAATGGCTCAAGAGCTCTTCCCTTCAA
GACTTTGATATTCGAGCAATTCTGGATTGGGACTACTACATTGAGCGGCTGGGAAGCGCC
ATCCAGAAGATCATCACCATCCCTGCGGCCCTGCAGCAGGTAAAGAACCCAGTGCCACGT
GTCAAACACCCCGACTGGCTGCACAAAAAACTGCTGGAGAAGAATGATGTCTACAAGCAG
AAGAAGATCAGTGAGCTCTTCACCCTGGAGGGCAGGAGACAGGTCACGATGGCCGAGGCC
TCAGAAGACAGTCCGAGGCCAAGTGCTCCTGACATGGAGGACTTCGGCCTCGTAAAGCTG
CCTCACCCAGCAGCCCCTGTCACTGTGAAGAGGAAGCGAGTTCTTTGGGAGAGCCAGGAG
GAGTCCCAGGACCTCACGCCGACTGTGCCCTGGCAGGAAATCTTGGGGCAGCCTCCCGCC
CTGGGAACCAGCCAGGAGGAATGGCTTGTCTGGCTCCGGTTCCACAAGAAGAAGTGGCAG
CTGCAGGCCCGGCAGCGCCTCGCCCGCAGGAAGAGGCAGCGTCTGGAGTCGGCAGAGGGT
GTGCTCAGGCCCGGGGCCATCCGGGATGGTCCTGCCACGGGGCTGGGGAGCTTCTTGCGA
AGAACTGCCCGCAGCATCCTGGACCTTCCGTGGCAGATTGTGCAGATCAGCGAGACCAGC
CAGGCCGGCCTGTTCAGGCTGTGGGCGCTCGTTGGCAGTGACTTGCACTGCATCAGGCTG
AGCATCCCCCGTGTGTTCTACGTGAACCAGCGAGTCGCTAAAGCGGAGGAGGGTGCTTCG
TATCGCAAGGTAAATCGGGTCCTTCCTCGCTCCAACATGGTCTACAATCTCTATGAGTAT
TCAGTGCCAGAGGACATGTACCAGGAACACATCAACGAGATCAACGCTGAGCTGTCAGCG
CCAGACATCGAGGGCGTATATGAGACTCAGGTTCCGTTACTGTTCCGGGCCCTGGTGCAC
CTGGGCTGTGTGTGTGTGGTCAATAAACAGCTGGTGAGGCACCTTTCAGGCTGGGAAGCA
GAGACCTTTGCTCTTGAGCACCTGGAGATGCGCTCTCTGGCCCAGTTCAGCTACCTGGAA
CCAGGGAGTATCCGCCATATCTACCTGTACCACCACGCACAGGCCCACAAAGCGCTCTTC
GGGATCTTCATCCCCTCACAGCGCAGGGCATCCGTCTTTGTGCTGGACACTGTGCGCAGC
AACCAGATGCCCAGCCTTGGCGCCCTGTACTCAGCAGAGCACGGCCTCCTCCTGGAGAAG
GTGGGCCCTGAGCTCCTGCCACCCCCCAAACACACCTTCGAAGTTCGGGCAGAAACTGAC
CTGAAGACCATCTGCAGAGCCATCCAGCGATTCCTGCTCGCCTACAAGGAGGAGCGCCGG
GGGCCCACACTCATCGCTGTTCAGTCCAGCTGGGAGCTGAAGAGGCTGGCCAGTGAAATT
CCTGTCTTGGAGGAATTCCCACTGGTGCCTATCTGTGTGGCTGACAAGATCAACTATGGG
GTCCTGGACTGGCAGCGCCATGGAGCCCGGCGCATGATCCGTCACTACCTCAACCTGGAC
ACCTGCCTGTCGCAGGCCTTCGAGATGAGCAGGTACTTTCACATTCCCATTGGGAACCTA
CCAGAGGACATCTCCACATTCGGCTCCGACCTCTTCTTTGCCCGCCACCTCCAGCGCCAC
AACCACCTGCTCTGGCTGTCCCCTACAGCCCGCCCTGACCTGGGTGGAAAGGAGGCTGAT
GACAACTGTCTTGTCATGGAGTTCGATGACCAAGCCACTGTTGAGATCAACAGTTCAGGC
TGTTACTCCACAGTGTGTGTGGAGCTGGACCTTCAGAACCTGGCCGTCAACACCATTCTC
CAGTCTCACCATGTCAACGACATGGAGGGGGCCGACAGCATGGGGATCAGCTTCGACGTG
ATCCAGCAGGCCTCCCTGGAGGACATGATCACGGGTGGTCAGGCTGCCAGTGCCCCGGCC
AGCTACGATGAGACAGCCCTGTGCTCTAACACCTTCAGGATCCTGAAGAGCATGGTCGTG
GGCTGGGTGAAGGAGATCACCCAGTACCACAACATCTATGCAGACAACCAGGTGATGCAC
TTCTACCGCTGGCTTCGGTCGCCATCCTCTCTGCTTCATGACCCTGCCCTGCACCGCACA
CTCCACAACATGATGAAGAAGCTCTTCCTGCAGCTCATCGCTGAGTTCAAGCGCCTGGGG
TCATCAGTCATCTACGCCAACTTCAACCGCATCATCCTCTGTACAAAGAAGCGCCGTGTG
GAAGATGCCATCGCTTACGTGGAGTACATCACCAGCAGCATCCATTCAAAGGAGACCTTC
CATTCTCTGACAATTTCTTTCTCTCGATGCTGGGAATTTCTTCTCTGGATGGATCCATCT
AACTATGGCGGAATCAAAGGAAAAGTTTCATCTCGTATTCACTGTGGACTGCAAGACTCC
CAGAAAGCAGGGGGAGCAGAGGATGAGCAGGAAAATGAGGACGATGAGGAGGAAAGAGAT
GGGGAGGAGGAGGAAGAGGCGGAGGAATCCAACGTGGAGGATTTACTGGAAAACAACTGG
AACATTTTGCAGTTTTTGCCACAGGCAGCCTCCTGCCAGAACTACTTCCTCATGATTGTT
TCAGCGTACATCGTGGCCGTGTACCACTGCATGAAGGACGGGCTGAGGCGCAGTGCTCCA
GGGAGCACCCCCGTGAGGAGGAGGGGGGCCAGCCAGCTCTCCCAGGAGGCCGAGGGGGCG
GTCGGAGCCCTTCCCGGAATGATCACCTTCTCTCAGGATTATGTCGCAAATGAGCTCACT
CAGAGCTTCTTCACCATCACTCAGAAGATTCAGAAGAAAGTCACAGGCTCTCGGAACTCC
ACTGAGCTCTCAGAGATGTTTCCTGTCCTCCCCGGTTCCCACTTGCTGCTCAATAACCCT
GCCCTGGAGTTCATCAAATACGTGTGCAAGGTGCTGTCCCTGGACACCAACATCACAAAC
CAGGTGAATAAGCTGAACCGAGACCTGCTTCGCCTGGTGGATGTCGGCGAGTTCTCCGAG
GAGGCCCAGTTCCGAGACCCCTGCCGCTCCTACGTGCTTCCTGAGGTCATCTGCCGCAGC
TGTAACTTCTGCCGCGACCTGGACCTGTGTAAAGACTCTTCCTTCTCAGAGGATGGGGCG
GTCCTGCCTCAGTGGCTCTGCTCCAACTGTCAGGCGCCCTACGACTCCTCTGCCATCGAG
ATGACGCTGGTGGAAGTTCTACAGAAGAAGCTGATGGCCTTCACCCTGCAGGACCTGGTC
TGCCTGAAGTGCCGCGGGGTGAAGGAGACCAGCATGCCTGTGTACTGCAGCTGCGCGGGA
GACTTCGCCCTCACCATCCACACCCAGGTCTTCATGGAACAGATCGGAATATTCCGGAAC
ATTGCCCAGCACTACGGCATGTCGTACCTCCTGGAGACCCTGGAGTGGCTGCTGCAGAAG
AACCCACAGCTGGGCCATTAG
|
| Protein Properties |
|---|
| Number of Residues
| 2286 |
| Molecular Weight
| 261515.525 |
| Theoretical pI
| 6.392 |
| Pfam Domain Function
|
|
| Signals
|
Not Available
|
|
Transmembrane Regions
|
Not Available
|
| Protein Sequence
|
>DNA polymerase epsilon catalytic subunit A
MSLRSGGRRRADPGADGEASRDDGATSSVSALKRLERSQWTDKMDLRFGFERLKEPGEKT
GWLINMHPTEILDEDKRLGSAVDYYFIQDDGSRFKVALPYKPYFYIATRKGCEREVSSFL
SKKFQGKIAKVETVPKEDLDLPNHLVGLKRNYIRLSFHTVEDLVKVRKEISPAVKKNREQ
DHASDAYTALLSSVLQRGGVITDEEETSKKIADQLDNIVDMREYDVPYHIRLSIDLKIHV
AHWYNVRYRGNAFPVEITRRDDLVERPDPVVLAFDIETTKLPLKFPDAETDQIMMISYMI
DGQGYLITNREIVSEDIEDFEFTPKPEYEGPFCVFNEPDEAHLIQRWFEHVQETKPTIMV
TYNGDFFDWPFVEARAAVHGLSMQQEIGFQKDSQGEYKAPQCIHMDCLRWVKRDSYLPVG
SHNLKAAAKAKLGYDPVELDPEDMCRMATEQPQTLATYSVSDAVATYYLYMKYVHPFIFA
LCTIIPMEPDEVLRKGSGTLCEALLMVQAFHANIIFPNKQEQEFNKLTDDGHVLDSETYV
GGHVEALESGVFRSDIPCRFRMNPAAFDFLLQRVEKTLRHALEEEEKVPVEQVTNFEEVC
DEIKSKLASLKDVPSRIECPLIYHLDVGAMYPNIILTNRLQPSAMVDEATCAACDFNKPG
ANCQRKMAWQWRGEFMPASRSEYHRIQHQLESEKFPPLFPEGPARAFHELSREEQAKYEK
RRLADYCRKAYKKIHITKVEERLTTICQRENSFYVDTVRAFRDRRYEFKGLHKVWKKKLS
AAVEVGDAAEVKRCKNMEVLYDSLQLAHKCILNSFYGYVMRKGARWYSMEMAGIVCFTGA
NIITQARELIEQIGRPLELDTDGIWCVLPNSFPENFVFKTTNVKKPKVTISYPGAMLNIM
VKEGFTNDQYQELAEPSSLTYVTRSENSIFFEVDGPYLAMILPASKEEGKKLKKRYAVFN
EDGSLAELKGFEVKRRGELQLIKIFQSSVFEAFLKGSTLEEVYGSVAKVADYWLDVLYSK
AANMPDSELFELISENRSMSRKLEDYGEQKSTSISTAKRLAEFLGDQMVKDAGLSCRYII
SRKPEGSPVTERAIPLAIFQAEPTVRKHFLRKWLKSSSLQDFDIRAILDWDYYIERLGSA
IQKIITIPAALQQVKNPVPRVKHPDWLHKKLLEKNDVYKQKKISELFTLEGRRQVTMAEA
SEDSPRPSAPDMEDFGLVKLPHPAAPVTVKRKRVLWESQEESQDLTPTVPWQEILGQPPA
LGTSQEEWLVWLRFHKKKWQLQARQRLARRKRQRLESAEGVLRPGAIRDGPATGLGSFLR
RTARSILDLPWQIVQISETSQAGLFRLWALVGSDLHCIRLSIPRVFYVNQRVAKAEEGAS
YRKVNRVLPRSNMVYNLYEYSVPEDMYQEHINEINAELSAPDIEGVYETQVPLLFRALVH
LGCVCVVNKQLVRHLSGWEAETFALEHLEMRSLAQFSYLEPGSIRHIYLYHHAQAHKALF
GIFIPSQRRASVFVLDTVRSNQMPSLGALYSAEHGLLLEKVGPELLPPPKHTFEVRAETD
LKTICRAIQRFLLAYKEERRGPTLIAVQSSWELKRLASEIPVLEEFPLVPICVADKINYG
VLDWQRHGARRMIRHYLNLDTCLSQAFEMSRYFHIPIGNLPEDISTFGSDLFFARHLQRH
NHLLWLSPTARPDLGGKEADDNCLVMEFDDQATVEINSSGCYSTVCVELDLQNLAVNTIL
QSHHVNDMEGADSMGISFDVIQQASLEDMITGGQAASAPASYDETALCSNTFRILKSMVV
GWVKEITQYHNIYADNQVMHFYRWLRSPSSLLHDPALHRTLHNMMKKLFLQLIAEFKRLG
SSVIYANFNRIILCTKKRRVEDAIAYVEYITSSIHSKETFHSLTISFSRCWEFLLWMDPS
NYGGIKGKVSSRIHCGLQDSQKAGGAEDEQENEDDEEERDGEEEEEAEESNVEDLLENNW
NILQFLPQAASCQNYFLMIVSAYIVAVYHCMKDGLRRSAPGSTPVRRRGASQLSQEAEGA
VGALPGMITFSQDYVANELTQSFFTITQKIQKKVTGSRNSTELSEMFPVLPGSHLLLNNP
ALEFIKYVCKVLSLDTNITNQVNKLNRDLLRLVDVGEFSEEAQFRDPCRSYVLPEVICRS
CNFCRDLDLCKDSSFSEDGAVLPQWLCSNCQAPYDSSAIEMTLVEVLQKKLMAFTLQDLV
CLKCRGVKETSMPVYCSCAGDFALTIHTQVFMEQIGIFRNIAQHYGMSYLLETLEWLLQK
NPQLGH
|
| External Links |
|---|
| GenBank ID Protein
| 62198237 |
| UniProtKB/Swiss-Prot ID
| Q07864 |
| UniProtKB/Swiss-Prot Entry Name
| DPOE1_HUMAN |
| PDB IDs
|
Not Available |
| GenBank Gene ID
| NM_006231.2 |
| GeneCard ID
| POLE |
| GenAtlas ID
| POLE |
| HGNC ID
| HGNC:9177 |
| References |
|---|
| General References
| Not Available |