Showing Protein CREB-binding protein (CDBP00014)
| Identification | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HMDB Protein ID | CDBP00014 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Secondary Accession Numbers | Not Available | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Name | CREB-binding protein | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Description | Not Available | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Synonyms | Not Available | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Gene Name | CREBBP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Protein Type | Enzyme | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Biological Properties | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| General Function | Involved in transcription cofactor activity | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Specific Function | Acetylates histones, giving a specific tag for transcriptional activation. Also acetylates non-histone proteins, like NCOA3 and FOXO1. Binds specifically to phosphorylated CREB and enhances its transcriptional activity toward cAMP-responsive genes. Acts as a coactivator of ALX1 in the presence of EP300. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GO Classification |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Cellular Location |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
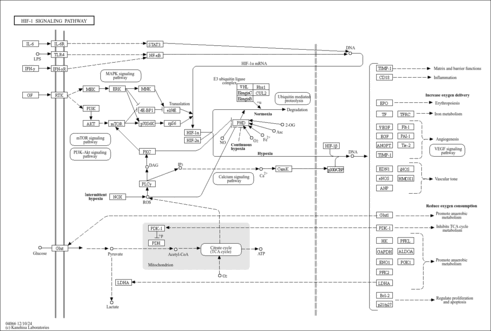
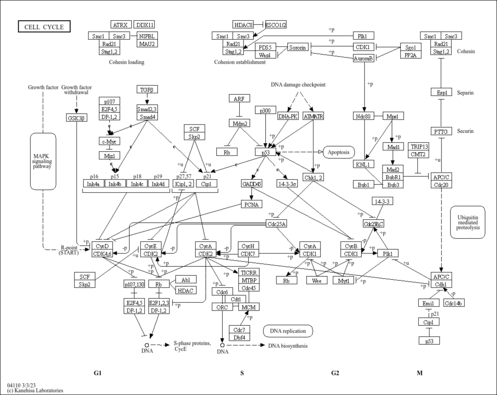
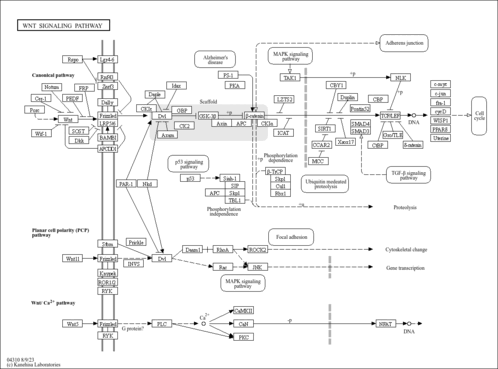
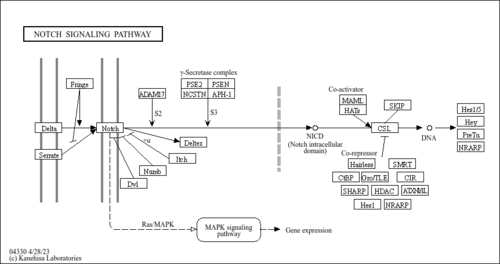
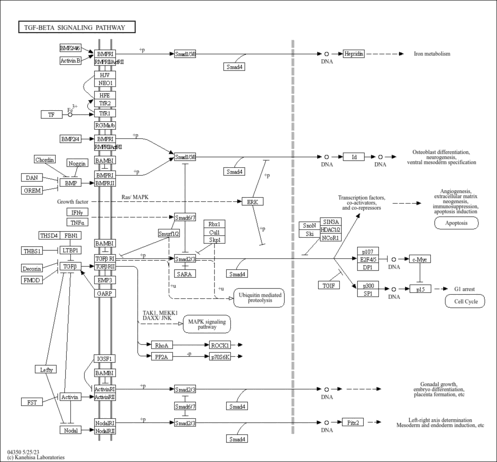
| Pathways |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Gene Properties | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Chromosome Location | 16 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Locus | 16p13.3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| SNPs | CREBBP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Gene Sequence |
>7329 bp ATGGCTGAGAACTTGCTGGACGGACCGCCCAACCCCAAAAGAGCCAAACTCAGCTCGCCC GGTTTCTCGGCGAATGACAGCACAGATTTTGGATCATTGTTTGACTTGGAAAATGATCTT CCTGATGAGCTGATACCCAATGGAGGAGAATTAGGCCTTTTAAACAGTGGGAACCTTGTT CCAGATGCTGCTTCCAAACATAAACAACTGTCGGAGCTTCTACGAGGAGGCAGCGGCTCT AGTATCAACCCAGGAATAGGAAATGTGAGCGCCAGCAGCCCCGTGCAGCAGGGCCTGGGT GGCCAGGCTCAAGGGCAGCCGAACAGTGCTAACATGGCCAGCCTCAGTGCCATGGGCAAG AGCCCTCTGAGCCAGGGAGATTCTTCAGCCCCCAGCCTGCCTAAACAGGCAGCCAGCACC TCTGGGCCCACCCCCGCTGCCTCCCAAGCACTGAATCCGCAAGCACAAAAGCAAGTGGGG CTGGCGACTAGCAGCCCTGCCACGTCACAGACTGGACCTGGTATCTGCATGAATGCTAAC TTTAACCAGACCCACCCAGGCCTCCTCAATAGTAACTCTGGCCATAGCTTAATTAATCAG GCTTCACAAGGGCAGGCGCAAGTCATGAATGGATCTCTTGGGGCTGCTGGCAGAGGAAGG GGAGCTGGAATGCCGTACCCTACTCCAGCCATGCAGGGCGCCTCGAGCAGCGTGCTGGCT GAGACCCTAACGCAGGTTTCCCCGCAAATGACTGGTCACGCGGGACTGAACACCGCACAG GCAGGAGGCATGGCCAAGATGGGAATAACTGGGAACACAAGTCCATTTGGACAGCCCTTT AGTCAAGCTGGAGGGCAGCCAATGGGAGCCACTGGAGTGAACCCCCAGTTAGCCAGCAAA CAGAGCATGGTCAACAGTTTGCCCACCTTCCCTACAGATATCAAGAATACTTCAGTCACC AACGTGCCAAATATGTCTCAGATGCAAACATCAGTGGGAATTGTACCCACACAAGCAATT GCAACAGGCCCCACTGCAGATCCTGAAAAACGCAAACTGATACAGCAGCAGCTGGTTCTA CTGCTTCATGCTCATAAGTGTCAGAGACGAGAGCAAGCAAACGGAGAGGTTCGGGCCTGC TCGCTCCCGCATTGTCGAACCATGAAAAACGTTTTGAATCACATGACGCATTGTCAGGCT GGGAAAGCCTGCCAAGTTGCCCATTGTGCATCTTCACGACAAATCATCTCTCATTGGAAG AACTGCACACGACATGACTGTCCTGTTTGCCTCCCTTTGAAAAATGCCAGTGACAAGCGA AACCAACAAACCATCCTGGGGTCTCCAGCTAGTGGAATTCAAAACACAATTGGTTCTGTT GGCACAGGGCAACAGAATGCCACTTCTTTAAGTAACCCAAATCCCATAGACCCCAGCTCC ATGCAGCGAGCCTATGCTGCTCTCGGACTCCCCTACATGAACCAGCCCCAGACGCAGCTG CAGCCTCAGGTTCCTGGCCAGCAACCAGCACAGCCTCAAACCCACCAGCAGATGAGGACT CTCAACCCCCTGGGAAATAATCCAATGAACATTCCAGCAGGAGGAATAACAACAGATCAG CAGCCCCCAAACTTGATTTCAGAATCAGCTCTTCCGACTTCCCTGGGGGCCACAAACCCA CTGATGAACGATGGCTCCAACTCTGGTAACATTGGAACCCTCAGCACTATACCAACAGCA GCTCCTCCTTCTAGCACCGGTGTAAGGAAAGGCTGGCACGAACATGTCACTCAGGACCTG CGGAGCCATCTAGTGCATAAACTCGTCCAAGCCATCTTCCCAACACCTGATCCCGCAGCT CTAAAGGATCGCCGCATGGAAAACCTGGTAGCCTATGCTAAGAAAGTGGAAGGGGACATG TACGAGTCTGCCAACAGCAGGGATGAATATTATCACTTATTAGCAGAGAAAATCTACAAG ATACAAAAAGAACTAGAAGAAAAACGGAGGTCGCGTTTACATAAACAAGGCATCTTGGGG AACCAGCCAGCCTTACCAGCCCCGGGGGCTCAGCCCCCTGTGATTCCACAGGCACAACCT GTGAGACCTCCAAATGGACCCCTGTCCCTGCCAGTGAATCGCATGCAAGTTTCTCAAGGG ATGAATTCATTTAACCCCATGTCCTTGGGGAACGTCCAGTTGCCACAAGCACCCATGGGA CCTCGTGCAGCCTCCCCAATGAACCACTCTGTCCAGATGAACAGCATGGGCTCAGTGCCA GGGATGGCCATTTCTCCTTCCCGAATGCCTCAGCCTCCGAACATGATGGGTGCACACACC AACAACATGATGGCCCAGGCGCCCGCTCAGAGCCAGTTTCTGCCACAGAACCAGTTCCCG TCATCCAGCGGGGCGATGAGTGTGGGCATGGGGCAGCCGCCAGCCCAAACAGGCGTGTCA CAGGGACAGGTGCCTGGTGCTGCTCTTCCTAACCCTCTCAACATGCTGGGGCCTCAGGCC AGCCAGCTACCTTGCCCTCCAGTGACACAGTCACCACTGCACCCAACACCGCCTCCTGCT TCCACGGCTGCTGGCATGCCATCTCTCCAGCACACGACACCACCTGGGATGACTCCTCCC CAGCCAGCAGCTCCCACTCAGCCATCAACTCCTGTGTCGTCTTCCGGGCAGACTCCCACC CCGACTCCTGGCTCAGTGCCCAGTGCTACCCAAACCCAGAGCACCCCTACAGTCCAGGCA GCAGCCCAGGCCCAGGTGACCCCGCAGCCTCAAACCCCAGTTCAGCCCCCGTCTGTGGCT ACCCCTCAGTCATCGCAGCAACAGCCGACGCCTGTGCACGCCCAGCCTCCTGGCACACCG CTTTCCCAGGCAGCAGCCAGCATTGATAACAGAGTCCCTACCCCCTCCTCGGTGGCCAGC GCAGAAACCAATTCCCAGCAGCCAGGACCTGACGTACCTGTGCTGGAAATGAAGACGGAG ACCCAAGCAGAGGACACTGAGCCCGATCCTGGTGAATCCAAAGGGGAGCCCAGGTCTGAG ATGATGGAGGAGGATTTGCAAGGAGCTTCCCAAGTTAAAGAAGAAACAGACATAGCAGAG CAGAAATCAGAACCAATGGAAGTGGATGAAAAGAAACCTGAAGTGAAAGTAGAAGTTAAA GAGGAAGAAGAGAGTAGCAGTAACGGCACAGCCTCTCAGTCAACATCTCCTTCGCAGCCG CGCAAAAAAATCTTTAAACCAGAGGAGTTACGCCAGGCCCTCATGCCAACCCTAGAAGCA CTGTATCGACAGGACCCAGAGTCATTACCTTTCCGGCAGCCTGTAGATCCCCAGCTCCTC GGAATTCCAGACTATTTTGACATCGTAAAGAATCCCATGGACCTCTCCACCATCAAGCGG AAGCTGGACACAGGGCAATACCAAGAGCCCTGGCAGTACGTGGACGACGTCTGGCTCATG TTCAACAATGCCTGGCTCTATAATCGCAAGACATCCCGAGTCTATAAGTTTTGCAGTAAG CTTGCAGAGGTCTTTGAGCAGGAAATTGACCCTGTCATGCAGTCCCTTGGATATTGCTGT GGACGCAAGTATGAGTTTTCCCCACAGACTTTGTGCTGCTATGGGAAGCAGCTGTGTACC ATTCCTCGCGATGCTGCCTACTACAGCTATCAGAATAGGTATCATTTCTGTGAGAAGTGT TTCACAGAGATCCAGGGCGAGAATGTGACCCTGGGTGACGACCCTTCACAGCCCCAGACG ACAATTTCAAAGGATCAGTTTGAAAAGAAGAAAAATGATACCTTAGACCCCGAACCTTTC GTTGATTGCAAGGAGTGTGGCCGGAAGATGCATCAGATTTGCGTTCTGCACTATGACATC ATTTGGCCTTCAGGTTTTGTGTGCGACAACTGCTTGAAGAAAACTGGCAGACCTCGAAAA GAAAACAAATTCAGTGCTAAGAGGCTGCAGACCACAAGACTGGGAAACCACTTGGAAGAC CGAGTGAACAAATTTTTGCGGCGCCAGAATCACCCTGAAGCCGGGGAGGTTTTTGTCCGA GTGGTGGCCAGCTCAGACAAGACGGTGGAGGTCAAGCCCGGGATGAAGTCACGGTTTGTG GATTCTGGGGAAATGTCTGAATCTTTCCCATATCGAACCAAAGCTCTGTTTGCTTTTGAG GAAATTGACGGCGTGGATGTCTGCTTTTTTGGAATGCACGTCCAAGAATACGGCTCTGAT TGCCCCCCTCCAAACACGAGGCGTGTGTACATTTCTTATCTGGATAGTATTCATTTCTTC CGGCCACGTTGCCTCCGCACAGCCGTTTACCATGAGATCCTTATTGGATATTTAGAGTAT GTGAAGAAATTAGGGTATGTGACAGGGCACATCTGGGCCTGTCCTCCAAGTGAAGGAGAT GATTACATCTTCCATTGCCACCCACCTGATCAAAAAATACCCAAGCCAAAACGACTGCAG GAGTGGTACAAAAAGATGCTGGACAAGGCGTTTGCAGAGCGGATCATCCATGACTACAAG GATATTTTCAAACAAGCAACTGAAGACAGGCTCACCAGTGCCAAGGAACTGCCCTATTTT GAAGGTGATTTCTGGCCCAATGTGTTAGAAGAGAGCATTAAGGAACTAGAACAAGAAGAA GAGGAGAGGAAAAAGGAAGAGAGCACTGCAGCCAGTGAAACCACTGAGGGCAGTCAGGGC GACAGCAAGAATGCCAAGAAGAAGAACAACAAGAAAACCAACAAGAACAAAAGCAGCATC AGCCGCGCCAACAAGAAGAAGCCCAGCATGCCCAACGTGTCCAATGACCTGTCCCAGAAG CTGTATGCCACCATGGAGAAGCACAAGGAGGTCTTCTTCGTGATCCACCTGCACGCTGGG CCTGTCATCAACACCCTGCCCCCCATCGTCGACCCCGACCCCCTGCTCAGCTGTGACCTC ATGGATGGGCGCGACGCCTTCCTCACCCTCGCCAGAGACAAGCACTGGGAGTTCTCCTCC TTGCGCCGCTCCAAGTGGTCCACGCTCTGCATGCTGGTGGAGCTGCACACCCAGGGCCAG GACCGCTTTGTCTACACCTGCAACGAGTGCAAGCACCACGTGGAGACGCGCTGGCACTGC ACTGTGTGCGAGGACTACGACCTCTGCATCAACTGCTATAACACGAAGAGCCATGCCCAT AAGATGGTGAAGTGGGGGCTGGGCCTGGATGACGAGGGCAGCAGCCAGGGCGAGCCACAG TCAAAGAGCCCCCAGGAGTCACGCCGGCTGAGCATCCAGCGCTGCATCCAGTCGCTGGTG CACGCGTGCCAGTGCCGCAACGCCAACTGCTCGCTGCCATCCTGCCAGAAGATGAAGCGG GTGGTGCAGCACACCAAGGGCTGCAAACGCAAGACCAACGGGGGCTGCCCGGTGTGCAAG CAGCTCATCGCCCTCTGCTGCTACCACGCCAAGCACTGCCAAGAAAACAAATGCCCCGTG CCCTTCTGCCTCAACATCAAACACAAGCTCCGCCAGCAGCAGATCCAGCACCGCCTGCAG CAGGCCCAGCTCATGCGCCGGCGGATGGCCACCATGAACACCCGCAACGTGCCTCAGCAG AGTCTGCCTTCTCCTACCTCAGCACCGCCCGGGACCCCCACACAGCAGCCCAGCACACCC CAGACGCCGCAGCCCCCTGCCCAGCCCCAACCCTCACCCGTGAGCATGTCACCAGCTGGC TTCCCCAGCGTGGCCCGGACTCAGCCCCCCACCACGGTGTCCACAGGGAAGCCTACCAGC CAGGTGCCGGCCCCCCCACCCCCGGCCCAGCCCCCTCCTGCAGCGGTGGAAGCGGCTCGG CAGATCGAGCGTGAGGCCCAGCAGCAGCAGCACCTGTACCGGGTGAACATCAACAACAGC ATGCCCCCAGGACGCACGGGCATGGGGACCCCGGGGAGCCAGATGGCCCCCGTGAGCCTG AATGTGCCCCGACCCAACCAGGTGAGCGGGCCCGTCATGCCCAGCATGCCTCCCGGGCAG TGGCAGCAGGCGCCCCTTCCCCAGCAGCAGCCCATGCCAGGCTTGCCCAGGCCTGTGATA TCCATGCAGGCCCAGGCGGCCGTGGCTGGGCCCCGGATGCCCAGCGTGCAGCCACCCAGG AGCATCTCACCCAGCGCTCTGCAAGACCTGCTGCGGACCCTGAAGTCGCCCAGCTCCCCT CAGCAGCAACAGCAGGTGCTGAACATTCTCAAATCAAACCCGCAGCTAATGGCAGCTTTC ATCAAACAGCGCACAGCCAAGTACGTGGCCAATCAGCCCGGCATGCAGCCCCAGCCTGGC CTCCAGTCCCAGCCCGGCATGCAACCCCAGCCTGGCATGCACCAGCAGCCCAGCCTGCAG AACCTGAATGCCATGCAGGCTGGCGTGCCGCGGCCCGGTGTGCCTCCACAGCAGCAGGCG ATGGGAGGCCTGAACCCCCAGGGCCAGGCCTTGAACATCATGAACCCAGGACACAACCCC AACATGGCGAGTATGAATCCACAGTACCGAGAAATGTTACGGAGGCAGCTGCTGCAGCAG CAGCAGCAACAGCAGCAGCAACAACAGCAGCAACAGCAGCAGCAGCAAGGGAGTGCCGGC ATGGCTGGGGGCATGGCGGGGCACGGCCAGTTCCAGCAGCCTCAAGGACCCGGAGGCTAC CCACCGGCCATGCAGCAGCAGCAGCGCATGCAGCAGCATCTCCCCCTCCAGGGCAGCTCC ATGGGCCAGATGGCGGCTCAGATGGGACAGCTTGGCCAGATGGGGCAGCCGGGGCTGGGG GCAGACAGCACCCCCAACATCCAGCAAGCCCTGCAGCAGCGGATTCTGCAGCAACAGCAG ATGAAGCAGCAGATTGGGTCCCCAGGCCAGCCGAACCCCATGAGCCCCCAGCAACACATG CTCTCAGGACAGCCACAGGCCTCGCATCTCCCTGGCCAGCAGATCGCCACGTCCCTTAGT AACCAGGTGCGGTCTCCAGCCCCTGTCCAGTCTCCACGGCCCCAGTCCCAGCCTCCACAT TCCAGCCCGTCACCACGGATACAGCCCCAGCCTTCGCCACACCACGTCTCACCCCAGACT GGTTCCCCCCACCCCGGACTCGCAGTCACCATGGCCAGCTCCATAGATCAGGGACACTTG GGGAACCCCGAACAGAGTGCAATGCTCCCCCAGCTGAACACCCCCAGCAGGAGTGCGCTG TCCAGCGAACTGTCCCTGGTCGGGGACACCACGGGGGACACGCTAGAGAAGTTTGTGGAG GGCTTGTAG |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Protein Properties | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Number of Residues | 2442 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Molecular Weight | 260991.825 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Theoretical pI | 8.475 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Pfam Domain Function | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Signals | Not Available | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Transmembrane Regions | Not Available | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Protein Sequence |
>CREB-binding protein MAENLLDGPPNPKRAKLSSPGFSANDSTDFGSLFDLENDLPDELIPNGGELGLLNSGNLV PDAASKHKQLSELLRGGSGSSINPGIGNVSASSPVQQGLGGQAQGQPNSANMASLSAMGK SPLSQGDSSAPSLPKQAASTSGPTPAASQALNPQAQKQVGLATSSPATSQTGPGICMNAN FNQTHPGLLNSNSGHSLINQASQGQAQVMNGSLGAAGRGRGAGMPYPTPAMQGASSSVLA ETLTQVSPQMTGHAGLNTAQAGGMAKMGITGNTSPFGQPFSQAGGQPMGATGVNPQLASK QSMVNSLPTFPTDIKNTSVTNVPNMSQMQTSVGIVPTQAIATGPTADPEKRKLIQQQLVL LLHAHKCQRREQANGEVRACSLPHCRTMKNVLNHMTHCQAGKACQVAHCASSRQIISHWK NCTRHDCPVCLPLKNASDKRNQQTILGSPASGIQNTIGSVGTGQQNATSLSNPNPIDPSS MQRAYAALGLPYMNQPQTQLQPQVPGQQPAQPQTHQQMRTLNPLGNNPMNIPAGGITTDQ QPPNLISESALPTSLGATNPLMNDGSNSGNIGTLSTIPTAAPPSSTGVRKGWHEHVTQDL RSHLVHKLVQAIFPTPDPAALKDRRMENLVAYAKKVEGDMYESANSRDEYYHLLAEKIYK IQKELEEKRRSRLHKQGILGNQPALPAPGAQPPVIPQAQPVRPPNGPLSLPVNRMQVSQG MNSFNPMSLGNVQLPQAPMGPRAASPMNHSVQMNSMGSVPGMAISPSRMPQPPNMMGAHT NNMMAQAPAQSQFLPQNQFPSSSGAMSVGMGQPPAQTGVSQGQVPGAALPNPLNMLGPQA SQLPCPPVTQSPLHPTPPPASTAAGMPSLQHTTPPGMTPPQPAAPTQPSTPVSSSGQTPT PTPGSVPSATQTQSTPTVQAAAQAQVTPQPQTPVQPPSVATPQSSQQQPTPVHAQPPGTP LSQAAASIDNRVPTPSSVASAETNSQQPGPDVPVLEMKTETQAEDTEPDPGESKGEPRSE MMEEDLQGASQVKEETDIAEQKSEPMEVDEKKPEVKVEVKEEEESSSNGTASQSTSPSQP RKKIFKPEELRQALMPTLEALYRQDPESLPFRQPVDPQLLGIPDYFDIVKNPMDLSTIKR KLDTGQYQEPWQYVDDVWLMFNNAWLYNRKTSRVYKFCSKLAEVFEQEIDPVMQSLGYCC GRKYEFSPQTLCCYGKQLCTIPRDAAYYSYQNRYHFCEKCFTEIQGENVTLGDDPSQPQT TISKDQFEKKKNDTLDPEPFVDCKECGRKMHQICVLHYDIIWPSGFVCDNCLKKTGRPRK ENKFSAKRLQTTRLGNHLEDRVNKFLRRQNHPEAGEVFVRVVASSDKTVEVKPGMKSRFV DSGEMSESFPYRTKALFAFEEIDGVDVCFFGMHVQEYGSDCPPPNTRRVYISYLDSIHFF RPRCLRTAVYHEILIGYLEYVKKLGYVTGHIWACPPSEGDDYIFHCHPPDQKIPKPKRLQ EWYKKMLDKAFAERIIHDYKDIFKQATEDRLTSAKELPYFEGDFWPNVLEESIKELEQEE EERKKEESTAASETTEGSQGDSKNAKKKNNKKTNKNKSSISRANKKKPSMPNVSNDLSQK LYATMEKHKEVFFVIHLHAGPVINTLPPIVDPDPLLSCDLMDGRDAFLTLARDKHWEFSS LRRSKWSTLCMLVELHTQGQDRFVYTCNECKHHVETRWHCTVCEDYDLCINCYNTKSHAH KMVKWGLGLDDEGSSQGEPQSKSPQESRRLSIQRCIQSLVHACQCRNANCSLPSCQKMKR VVQHTKGCKRKTNGGCPVCKQLIALCCYHAKHCQENKCPVPFCLNIKHKLRQQQIQHRLQ QAQLMRRRMATMNTRNVPQQSLPSPTSAPPGTPTQQPSTPQTPQPPAQPQPSPVSMSPAG FPSVARTQPPTTVSTGKPTSQVPAPPPPAQPPPAAVEAARQIEREAQQQQHLYRVNINNS MPPGRTGMGTPGSQMAPVSLNVPRPNQVSGPVMPSMPPGQWQQAPLPQQQPMPGLPRPVI SMQAQAAVAGPRMPSVQPPRSISPSALQDLLRTLKSPSSPQQQQQVLNILKSNPQLMAAF IKQRTAKYVANQPGMQPQPGLQSQPGMQPQPGMHQQPSLQNLNAMQAGVPRPGVPPQQQA MGGLNPQGQALNIMNPGHNPNMASMNPQYREMLRRQLLQQQQQQQQQQQQQQQQQQGSAG MAGGMAGHGQFQQPQGPGGYPPAMQQQQRMQQHLPLQGSSMGQMAAQMGQLGQMGQPGLG ADSTPNIQQALQQRILQQQQMKQQIGSPGQPNPMSPQQHMLSGQPQASHLPGQQIATSLS NQVRSPAPVQSPRPQSQPPHSSPSPRIQPQPSPHHVSPQTGSPHPGLAVTMASSIDQGHL GNPEQSAMLPQLNTPSRSALSSELSLVGDTTGDTLEKFVEGL |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| External Links | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GenBank ID Protein | 68533141 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| UniProtKB/Swiss-Prot ID | Q92793 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| UniProtKB/Swiss-Prot Entry Name | CBP_HUMAN | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| PDB IDs | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GenBank Gene ID | U85962 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GeneCard ID | CREBBP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| GenAtlas ID | CREBBP | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| HGNC ID | HGNC:2348 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| References | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| General References | Not Available | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||